Se bienvenido a estas tierras digitales...
...especialmente si eres un molino....
Controles de privacidad digital: Análisis interdisciplinario desde la informática y el derecho.

Introducción
En un mundo cada vez más conectado, la privacidad digital se ha convertido en un punto focal tanto para tecnólogos como para juristas. La reciente columna de Eman Alashwali titulada “Two Types of Data-Privacy Controls” (Communications of the ACM, agosto de 2025) subraya la distinción fundamental entre dos modalidades de control de la privacidad de los datos: por un lado, la privacidad entre usuarios (es decir, la visibilidad social de la información personal frente a otros individuos) y, por otro lado, la privacidad entre el usuario y las instituciones (el control sobre cómo las organizaciones o servicios utilizan los datos del usuario). Alashwali argumenta que muchas plataformas han mejorado principalmente los controles del primer tipo (p. ej., quién puede ver nuestras publicaciones), mientras pasan por alto o son menos transparentes respecto al segundo tipo (cómo la empresa o terceros explotan nuestros datos). Esto puede generar en los usuarios una falsa sensación de control sobre su información, al creer que protegen su privacidad cuando en realidad solo controlan la exposición social, mientras que el uso institucional de sus datos sigue ocurriendo entre bastidores. La tesis de Alashwali plantea, por tanto, la necesidad de diferenciar y equilibrar ambos tipos de controles para evitar confusiones y proteger efectivamente la privacidad.
Privacidad entre usuarios vs. privacidad frente a instituciones
Diversos investigadores han reconocido la dualidad conceptual señalada por Alashwali empleando distintas terminologías. Por ejemplo, Raynes-Goldie (2010) acuñó los términos “privacidad social” (en relación con otros usuarios) versus “privacidad institucional” (frente a entidades como plataformas o gobiernos). Heyman et al. (2014) hablaron de privacidad “como sujeto” para referirse al control de lo que un usuario revela a otros usuarios, frente a privacidad “como objeto” para referirse al control sobre lo que se revela a terceros (donde el individuo es visto como objeto de minería de datos). En una línea similar, Brandimarte, Acquisti y Loewenstein (2013) clasificaron los controles de privacidad según su propósito: los controles de divulgación (release controls) que regulan la información compartida entre personas, y los controles de uso (usage controls) que regulan cómo los proveedores de servicios o terceros utilizan la información del usuario. Más recientemente, Bazarova y Masur (2020) propusieron integrar enfoques individualistas, de red y institucional para entender la divulgación y privacidad en entornos en línea, distinguiendo explícitamente entre un enfoque “en red” donde la información fluye horizontalmente entre usuarios, y un enfoque “institucional” donde los datos fluyen verticalmente entre el usuario y la institución que los recoge. Estas conceptualizaciones subrayan que la privacidad opera en diferentes dimensiones (la interpersonal y la institucional) y que requieren soluciones de control distintas.
La distinción entre privacidad social y privacidad institucional no es meramente teórica, sino que tiene consecuencias prácticas importantes. Como señala Alashwali, en los últimos años las plataformas digitales (redes sociales, servicios web, etc.) han tendido a enfatizar los controles “user-to-user”, por ejemplo, permitiendo configurar quién ve el perfil o determinadas publicaciones, mejorando así la autogestión de la visibilidad de la información frente a pares. Sin embargo, esos mismos servicios con frecuencia ofrecen un control mucho más limitado sobre el uso secundario que la empresa hace de los datos recopilados (perfilado para publicidad, compartición con terceros, retención prolongada de información personal, etc.). Cuando se ignora la diferencia entre estas dos capas de privacidad, es común que el usuario medio experimente una disonancia: puede sentirse seguro por saber manejar ajustes de confidencialidad en su perfil público, mientras desconoce las operaciones menos visibles que ocurren con sus datos a nivel institucional. Esto puede llevar a lo que algunos investigadores llaman la “paradoja del control”: a mayor percepción de control en la esfera social, menor preocupación por la privacidad en general, aun cuando persistan riesgos significativos en la esfera institucional. Un ejemplo claro es la situación descrita por Stutzman como los “oyentes silenciosos” en redes sociales: el usuario se preocupa por quién de sus contactos ve una publicación comprometedora, pero quizá pase por alto que anunciantes o terceros analizan esa misma publicación para perfilarlo, porque ese proceso es invisible para él. La cuestión es aún más preocupante cuando países como Estados Unidos, previo a la concesión del ESTA requiere que tengas abiertos tus perfiles en redes sociales….
Desde una perspectiva jurídica, la dimensión usuario-institución de la privacidad es la que típicamente abordan las leyes de protección de datos. El derecho a la protección de datos personales se enfoca, grosso modo, en regular cómo las organizaciones recogen, utilizan y comparten los datos personales, otorgando al individuo derechos (derecho de acceso, rectificación, supresión, oposición, etc.) y estableciendo obligaciones para los responsables del tratamiento (deber de obtener consentimiento válido, respetar finalidades declaradas, garantizar seguridad, etc.). Podría decirse que las leyes como el Reglamento General de Protección de Datos (RGPD) de la UE codifican mecanismos de “privacidad frente a la institución”: por ejemplo, obligando a que el tratamiento tenga una base legal (como el consentimiento del interesado), limitando la retención y uso de datos al propósito original, y exigiendo transparencia sobre dichas prácticas. En cambio, la privacidad entre usuarios ha sido tradicionalmente terreno de la autogestión (configuraciones que cada individuo aplica) y, en ciertos ámbitos, de normas específicas (p. ej., leyes contra el ciberacoso, difusión no consentida de imágenes íntimas, etc., que protegen la privacidad interpersonal en contextos particulares). Esto refleja un desajuste: la protección institucional depende más de obligaciones legales y arquitecturas internas del sistema, mientras que la protección social es más visible y tangible para el usuario final a través de interfaces y opciones. De ahí la importancia de combinar ambas perspectivas: un diseño socio-técnico integral de la privacidad debe brindar al usuario controles significativos en ambas dimensiones (qué comparte y con quién, y qué se hace con sus datos tras compartirlos), apoyados tanto por buenas prácticas de ingeniería como por garantías legales.
Legislación y computación en el control de datos
Los modelos de control de datos personales difieren en su origen disciplinar. Desde la óptica jurídica (especialmente en la tradición europea de protección de datos), el control se articula en torno a principios legales y derechos del individuo sobre su información. Un principio central es el del consentimiento informado del titular: ningún dato personal debe tratarse legítimamente sin una justificación legal, siendo la más paradigmática el consentimiento libre, específico e informado de la persona. De hecho, en palabras de un análisis comparado, el consentimiento se considera “la piedra angular del derecho de protección de datos” en sistemas como el europeo (referencia). A este se suman otros principios complementarios, como la limitación de la finalidad del tratamiento (usar los datos únicamente para el propósito legítimo declarado), la minimización de datos (recolectar solo los datos adecuados, pertinentes y estrictamente necesarios), la exactitud (mantenerlos actualizados y corregir errores), la limitación del plazo de conservación y la integridad y confidencialidad (seguridad) de los datos. Estos principios conforman un modelo jurídico donde el control se ejerce mediante la imposición de obligaciones a los responsables: deben pedir consentimiento o tener otra base legal, informar al usuario y respetar sus elecciones, no extralimitarse en el uso de la información y protegerla debidamente. Además, el individuo cuenta con derechos accionables (acceder a sus datos, rectificar errores, oponerse a ciertos tratamientos, revocar consentimiento, etc.) que le permiten intervenir en el ciclo de vida de sus datos. En suma, el derecho construye el control de la privacidad como un conjunto de garantías normativas y mecanismos de cumplimiento que buscan darle al ciudadano agencia sobre sus datos frente a las organizaciones.
Desde la perspectiva computacional, por otro lado, el control de datos se plasma en mecanismos técnicos e interfaces de usuario diseñadas para implementar esas intenciones. En sistemas informáticos, el control suele tomar la forma de controles de acceso y de flujo de información: quién puede acceder a qué datos, bajo qué condiciones, y cómo se restringe su propagación. Por ejemplo, a nivel de arquitectura técnica, se utilizan modelos de autorización (listas de control de acceso, roles de usuario con diferentes permisos, políticas de compartición), cifrado y anonimización (para limitar la legibilidad de los datos a quienes tengan la clave o para remover identificadores personales), y auditorías y registros (logs) que permiten rastrear usos indebidos. Muchos de estos controles informáticos se centran en la dimensión “entre usuarios”: las configuraciones de privacidad de una red social, por ejemplo, son implementadas por funciones en el software que filtran quién puede ver cierto contenido. Sin embargo, controlar el “uso institucional” de los datos mediante la tecnología es más complejo. Una vez que el dato ha sido entregado a una entidad (y podemos extender la inquietud a los monederos digitales) , impedir por medios puramente técnicos que esta lo analice o transmita a terceros requiere enfoques más avanzados, como políticas de uso declarativas incrustadas en los datos (un área de investigación conocida como uso controlado de la información), o técnicas criptográficas que permiten cierto procesamiento de datos sin revelarlos plenamente (p. ej., computación homomórfica o comparticiones seguras). En la práctica, muchas instituciones se rigen por mecanismos de gobernanza interna de datos: protocolos empresariales sobre quién dentro de la organización puede consultar ciertos datos (por ejemplo, compartimentar bases de datos de clientes, limitar acceso del personal salvo necesidad justificada), y herramientas que aplican automáticamente políticas de retención o anonimización después de cumplido el propósito.
Un punto crucial donde confluyen ambos enfoques es en el concepto de “controles de uso” de la información. Como mencionamos, Brandimarte et al. definieron los usage controls (controles de uso) como aquellos dirigidos a restringir cómo el proveedor del servicio o terceros pueden utilizar la información del usuario. Jurídicamente, esto se aborda con cláusulas legales y supervisión regulatoria; computacionalmente, se intenta abordar mediante diseños que limiten técnicamente esos usos. Un ejemplo son las opciones de opt-out o ajustes dentro de una plataforma para desactivar la personalización de anuncios: si bien se presentan al usuario como una casilla en la interfaz (una implementación técnica de preferencia), reflejan en el fondo una exigencia legal de permitir al individuo oponerse a ciertos tratamientos (perfilado, marketing) y una lógica de respeto a la finalidad original. Otro ejemplo más sofisticado es la incorporación de técnicas de privacidad diferencial (que discutiremos más adelante) en sistemas de análisis de datos: desde la perspectiva legal, sería una forma de cumplir con la obligación de no divulgar datos personales no agregados; desde la ingeniería, es un mecanismo matemático que controla la divulgación de información estadística con garantías formales. Vemos así que los modelos computacionales tienden a materializar el control de formas muy específicas (configuraciones binarías, algoritmos de restricción, protocolos de seguridad), mientras que los modelos jurídicos proporcionan el marco normativo y los principios abstractos que deben guiar esas implementaciones. La interacción efectiva entre ambos mundos (law in books y law in code) es fundamental para que los controles de privacidad sean realmente operativos: si la ley exige algo inviable técnicamente, quedará en letra muerta; si la tecnología ofrece opciones sin respaldo legal o sin una alineación con derechos, el control puede ser fácilmente soslayado por los poderosos (por ejemplo, un ajuste en la app que de nada sirve si la compañía puede cambiar unilateralmente sus términos). La disciplina emergente de la “privacidad desde la ingeniería” o “privacy engineering” precisamente busca traducir estos principios legales en requisitos y soluciones técnicas, y viceversa, lograr que las arquitecturas informáticas informen regulaciones más realistas. Como apuntan algunos autores, la ingeniería de la privacidad forma parte de un imaginario tecno-regulatorio más amplio donde las protecciones de derechos fundamentales se internalizan en el diseño tecnológico como una forma de regulación en sí misma (referencia).
Críticas y alternativas al consentimiento
Históricamente, el consentimiento informado del usuario ha sido la piedra angular de la protección de la privacidad, tanto en el discurso legal como en la práctica industrial. Sin embargo, han surgido tendencias entre los académicos de diversas disciplinas señalando las limitaciones y fallas sistémicas de este modelo de “aviso y elección” (notice-and-choice). Richards y Hartzog (2019) se refieren a las múltiples formas en que el consentimiento digital fracasa en la práctica como las “patologías del consentimiento”. Destacan que en el entorno digital actual se pide a los usuarios que consientan constantemente (a términos de servicio interminables, a políticas de privacidad opacas, al uso de cookies y rastreadores, etc.) y bajo condiciones muy lejos del ideal de un consentimiento plenamente libre y consciente. De hecho, aunque la teoría presume que el consentimiento refleja una elección informada, la realidad es que a menudo los usuarios clican “Aceptar” sin leer ni comprender (sea por fatiga, por necesidad de acceder al servicio, o porque la alternativa es no usar la tecnología). Esta brecha entre el ideal y la práctica genera varios “defectos” o patologías: consentimientos obtenidos bajo coacción indirecta (ej. “o aceptas las condiciones o no puedes usar el servicio”), consentimientos no leídos o no entendidos (jerga legal o técnica inabordable para el ciudadano medio), y consentimientos prácticamente vacíos de elección (pues todos los proveedores imponen condiciones similares, dejando al usuario sin opciones reales en el mercado digital). Lejos de ser un auténtico control para el individuo, el consentimiento se convierte muchas veces en un mecanismo de transferencia de responsabilidad: la empresa se blinda legalmente (“el usuario aceptó”) mientras el usuario, abrumado, cede datos.
Una de las consecuencias más discutidas de este fenómeno es la llamada “paradoja de la privacidad”: la aparente inconsistencia entre las actitudes de los usuarios (que suelen declarar preocupación por su privacidad) y su comportamiento (que frecuentemente la ceden con facilidad). Estudios recientes argumentan que esta paradoja no necesariamente implica hipocresía o desinterés de los usuarios, sino que refleja cómo el entorno de consentimiento forzado distorsiona sus decisiones. En palabras de Richards y Hartzog, las patologías del consentimiento explican cómo los consumidores pueden ser “empujados y manipulados” por empresas poderosas en contra de sus verdaderos intereses, especialmente cuando las protecciones legales están lejos del estándar ideal. Por ejemplo, un usuario puede terminar compartiendo más datos de los que querría simplemente porque la interfaz de consentimiento está diseñada con patrones manipulativos (dark patterns) que lo conducen a ello. Investigaciones en el campo de la interacción humano-computadora (HCI) han documentado la prevalencia de estos dark patterns en las interfaces de privacidad, particularmente en los banners de cookies introducidos tras el RGPD. Utz et al. (2019) hallaron que tácticas de “interferencia de interfaz” tales como resaltar visualmente el botón “Aceptar” en un cuadro de consentimiento, mientras se oculta o dificulta la opción de “Rechazar”, o presentar ciertas casillas ya pre-marcadas a favor del consentimiento, aumentan significativamente la tasa de aceptación de cookies de terceros por parte de los usuarios (ver referencia). Del mismo modo, Nouwens et al. (2020) y Matte et al. (2020) reportaron que una proporción sustancial de sitios emplean diseños que vulneran el requisito legal de un consentimiento libre: por ejemplo, muros de consentimiento que bloquean el acceso hasta aceptar (lo cual difícilmente es “libre”), o largas listas de propósitos poco claras con el botón de opt-out deliberadamente escondido. Estas prácticas erosionan la efectividad del consentimiento como salvaguarda, convirtiéndolo en un trámite superficial que legitima prácticamente cualquier tratamiento de datos.
Debido a lo anterior, numerosos académicos y legisladores están replanteando el paradigma. Una línea de crítica aboga por reducir la carga del consentimiento individual y fortalecer las responsabilidades proactivas de las organizaciones. En lugar de esperar que cada usuario lea centenares de avisos y tome decisiones informadas para cada ínfimo tratamiento de datos, se postula que la ley debe imponer deberes de lealtad y cuidado a las entidades que manejan información personal. Por ejemplo, Richards y Hartzog proponen pasar hacia un modelo basado en la confianza: conceptos como el de “fiduciario de datos” o “lealtad del tratamiento” implican que las empresas tendrían un deber legal de actuar en el mejor interés de los usuarios en cuanto a sus datos, evitando usos que los perjudiquen, independiente de que hayan obtenido o no un consentimiento técnico (y a veces hasta de cuestionable legitimidad). Esto encaja con ideas procedentes del derecho de consumo y de la ética empresarial: así como un asesor financiero debe actuar en beneficio de su cliente y no aprovecharse aunque el cliente firme algo, un controlador de datos debería tener límites claros que van más allá de obtener un clic de “Acepto”. Otras propuestas complementarias incluyen mejorar la transparencia y comprensibilidad de las políticas (aunque la eficacia de meras mejoras informativas es debatida), y especialmente el diseño de interfaces centradas en la privacidad. Aquí la informática y el derecho convergen: si la ley exige consentimiento “informado” y “libre”, el diseño debe facilitar realmente decisiones libres e informadas, no obstaculizarlas. Este entendimiento ha llevado a discusiones sobre la necesidad de regular o guiar las interfaces (por ejemplo, prohibiendo ciertos dark patterns en formularios de consentimiento, o estandarizando iconos y frases claras para opciones de privacidad). En síntesis, la tendencia actual es reconocer que el consentimiento, aunque es importante, no puede ser el único pilar, debe integrarse en una estrategia de protección más amplia que incluya responsabilidad demostrable de los responsables, controles técnicos efectivos y quizás modelos alternativos de autorización para ciertos usos de datos (por ejemplo, basados en evaluaciones de interés público o riesgos, más que en pedir permiso individual para todo). Este giro conceptual representa un esfuerzo por re-equilibrar la carga de la privacidad: aligerarla del individuo y colocar más obligaciones en quienes diseñan y operan los sistemas de información.
Diseño, arquitectura técnica y normativa: intersecciones clave
Una de las áreas más fértiles en la investigación reciente sobre privacidad es la intersección entre el diseño de sistemas (HCI, ingeniería de software) y las exigencias legales. Tradicionalmente, los expertos en usabilidad y los juristas han trabajado en paralelo, con poca interacción directa. Sin embargo, el advenimiento de marcos regulatorios estrictos como el RGPD y la creciente conciencia de que las interfaces pueden habilitar o socavar derechos, han impulsado enfoques interdisciplinarios. Un ejemplo emblemático es el análisis de banners de consentimiento de cookies desde una perspectiva tanto de experiencia de usuario como jurídica. Gray et al. (2021) llevaron a cabo un estudio interdisciplinario aplicando la noción de dark patterns para examinar hasta qué punto distintos diseños de avisos de consentimiento cumplen (o violan) los requisitos legales de consentimiento en la UE (ver referencia). Su trabajo reunió perspectivas de diseño de interacción, privacidad informática y derecho de protección de datos, identificando tensiones y sinergias: por ejemplo, descubrieron que ciertos diseños persiguen la aceptación del usuario a costa de principios legales como la libre elección, generando conflictos entre lo que sería una buena UX para la empresa (más datos recolectados) y el cumplimiento normativo estricto. Concluyen señalando la necesidad de un diálogo interdisciplinario entre las comunidades de informática, diseño, ética y derecho para traducir las preocupaciones éticas en políticas públicas y, a la vez, para guiar a los diseñadores hacia soluciones que respeten efectivamente los derechos. En la misma línea, Santos et al (2021) enfatizan que la investigación legal raras veces intersecta con HCI, y que abordar lagunas en cumplimiento (como la identificación de qué dark patterns podrían ser declarados ilegales bajo ciertas leyes) exige colaboraciones profundas entre ambas áreas.
Otro estudio reciente, de Rohan Grover (2024), exploró cómo los desarrolladores de software internalizan y ejecutan las tareas de cumplimiento de la protección de datos en su trabajo cotidiano (“Encoding Privacy: Sociotechnical Dynamics of Data Protection Compliance Work”). Sus hallazgos son reveladores: cuando normativas como el RGPD entran en juego, no solo actúan como restricciones, sino que también abren un espacio para que los ingenieros den forma a la implementación práctica de la ley en sus organizaciones (ver referencia). En otras palabras, los trabajadores técnicos median la ley, interpretando conceptos jurídicos abstractos (como “diseño por defecto” o “medidas técnicas apropiadas”) y traduciéndolos en decisiones concretas de producto. Grover observó que algunos desarrolladores en Norteamérica vieron en el RGPD una oportunidad profesional para influir internamente: por ejemplo, definiendo junto con sus equipos qué significa realmente el “espíritu de la ley” y cómo lograr que las prácticas de la empresa estén acordes con él. Esto apunta a una evolución interesante del rol del ingeniero/arquitecto: de ser meros receptores de requisitos legales a convertirse en co-creadores de cumplimiento, actuando como puentes entre abogados y sistemas. Sin embargo, este rol no está exento de desafíos: investigaciones de Gray et al. (2024) con profesionales de experiencia de usuario encontraron que muchos diseñadores carecen de formación o apoyo para entender asuntos legales, lo que produce incertidumbre e inconsistencia en cómo integran (o ignoran) consideraciones regulatorias en los proyectos. Estos estudios de caso resaltan la necesidad de dotar a los equipos técnicos de herramientas, conocimientos y “traducción” legal para que puedan incorporar la privacidad de modo robusto.
En general, la literatura reciente converge en que la colaboración multidisciplinar es imprescindible: HCI, ingeniería y derecho deben informarse mutuamente. Por un lado, el diseño centrado en el usuario puede ofrecer perspectivas sobre cómo implementar controles de privacidad que sean comprensibles y usables (de nada sirve una opción de privacidad si está escondida o resulta confusa, pues su protección será ilusoria). Por otro lado, la regulación proporciona objetivos y límites claros que el diseño debe respetar para evitar abusos (por ejemplo, el marco legal define que un consentimiento válido no puede lograrse mediante engaño o preselección, lo que debería descartar ciertos patrones de interfaz). Algunos académicos incluso ven esta convergencia como una oportunidad para que la comunidad de diseño influya en las políticas públicas: proponiendo mejores estándares de transparencia, evidenciando qué prácticas técnicas resultan más equitativas, etc. En suma, la intersección de arquitectura técnica y normativa legal está dando lugar a un espacio de investigación socio-técnica dinámico. Sus frutos se manifiestan en conceptos como “regulación mediante diseño” (advocando que parte de la regulación se implemente directamente a nivel de código) y “diseño con conciencia regulatoria”. Para usuarios y desarrolladores, esta tendencia promete experiencias más seguras por construcción, donde la protección de datos no dependa únicamente de leer cláusulas legales, sino que esté incorporada en cómo funcionan las aplicaciones desde el primer momento.
Principios y técnicas emergentes para la privacidad en sistemas sociotécnicos
A continuación, analizamos brevemente algunos conceptos clave (surgidos en la intersección del derecho y la computación) que ilustran cómo se están diseñando mecanismos de control de privacidad integrando ambas perspectivas:
Privacidad desde el diseño (Privacy by Design): Originalmente formulado por la experta Ann Cavoukian en la década de 1990, este principio postula que la protección de la privacidad no debe ser un añadido posterior, sino parte intrínseca del proceso de diseño y desarrollo de sistemas. En la actualidad, “Privacy by Design” ha sido consagrado legalmente, por ejemplo en el Artículo 25 del RGPD bajo la denominación “Protección de datos desde el diseño y por defecto”. Esto obliga a responsables y desarrolladores a incorporar salvaguardas de privacidad desde las primeras fases de concepción de un producto, así como a establecer configuraciones iniciales respetuosas con la privacidad (privacy by default). ¿Qué implica en la práctica? Medidas como la pseudonimización o el cifrado de datos sensibles por defecto, interfaces que ofrecen controles claros al usuario, y minimizar la recolección de datos innecesarios (en línea con el principio de minimización). Desde la perspectiva regulatoria europea, se trata de un cambio de paradigma: la ley espera activamente que la tecnología contribuya a la protección de derechos. Algunos académicos describen esta visión normativa como un “imaginario tecno-regulatorio” que “prescribe que para que el tratamiento de datos sea legítimo, debe incluir protecciones de los derechos y valores incorporadas en las propias tecnologías, en las organizaciones y en las agendas digitales futuras”. En otras palabras, la privacidad por diseño es la idea de que el cumplimiento legal se logre en gran medida mediante soluciones técnicas y de diseño, y no solo con promesas o documentos. No obstante, implementar Privacy by Design presenta retos: requiere una estrecha colaboración entre abogados, ingenieros y diseñadores, metodologías de privacy engineering que permitan traducir principios abstractos en requisitos técnicos verificables, y a veces enfrentarse a tensiones con otros objetivos (p. ej., usabilidad vs. seguridad, o recolección de datos para negocio vs. minimización). Aun así, en la última década ha surgido abundante literatura y guías prácticas sobre cómo llevar Privacy by Design a cabo, reflejando una convergencia entre la teoría legal y la práctica de la ingeniería.
Minimización de datos: Este principio, ya mencionado, es un pilar de la protección legal de datos personales y a la vez una guía para la arquitectura de sistemas. En esencia, la minimización establece que una entidad debe recopilar y retener únicamente la cantidad mínima de datos personales necesaria para cumplir con un propósito legítimo. El RGPD lo formula así: los datos personales han de ser “adecuados, pertinentes y limitados a lo necesario en relación con los fines para los que son tratados”. Traducido a diseños técnicos, esto supone tomar decisiones como: evitar solicitar datos innecesarios en formularios (¿realmente precisamos la fecha de nacimiento del usuario para brindarle un servicio de entrega de comida?); anonimizar o borrar atributos que no se utilicen activamente; agregar por defecto (por ejemplo, almacenar solo estadísticas en vez de datos brutos identificables cuando se pueda); y establecer plazos de eliminación o anonimización automática de registros una vez dejan de ser requeridos. La minimización contrasta con la tentación común en la ingeniería de “coleccionar todo por si acaso es útil luego”, práctica que, aparte de chocar con la ley, aumenta la superficie de riesgo en caso de brechas de seguridad. Desde la óptica jurídica, la minimización de datos protege al individuo reduciendo su “exposición” informativa; desde la óptica computacional, puede verse también como una mejora de seguridad y eficiencia (menos datos implica menos responsabilidad de custodia y a veces un procesamiento más ágil). Implementar verdaderamente este principio a veces exige creatividad técnica y vencer inercias culturales (p.ej., equipar a los equipos con metodologías de Data Protection Impact Assessment para justificar cada dato recolectado). En cualquier caso, la minimización actúa como un puente claro entre el derecho y el diseño de software: es un mandato legal que depende totalmente de decisiones arquitectónicas concretas.
Limitación de la finalidad: Íntimamente ligado al anterior, el principio de limitación de la finalidad dispone que los datos personales solo deben utilizarse para las finalidades explícitas y legítimas para las que fueron recogidos, y no ser tratados posteriormente de manera incompatible con esos fines. Este principio impone un marco de control temporal y contextual al uso de la información. Si una empresa recoge, por ejemplo, la dirección de email de un usuario para enviarle un recibo de compra, no debería reutilizar ese email para campañas de marketing no solicitadas, a menos que obtenga un nuevo consentimiento o tenga otra base legal. En términos legales, este principio fuerza a delimitar claramente el propósito en el momento de la recogida y vincular contractualmente al responsable a ello. Desde el punto de vista técnico, respetar la limitación de finalidad requiere mecanismos organizativos y a veces automatizados: clasificar los datos según su propósito, separar bases de datos o accesos por finalidad, y aplicar reglas que eviten cruces indebidos. Un diseño bien pensado podría, por ejemplo, mantener los datos analíticos agregados separados de los datos identificativos, o purgar ciertos campos una vez cumplido el trámite original (borrado después de X días si ya no se necesitan). Sin embargo, es notoriamente difícil generar políticas para esto técnicamente una vez que los datos están en poder de una organización; en gran medida se confía en la autorregulación y auditorías. Algunos investigadores sugieren que nuevas arquitecturas de gestión de consentimientos y políticas podrían reforzar este principio, por ejemplo, emergen estándares para adjuntar metadatos de propósito a los datos, de modo que cualquier uso posterior incompatibile pueda ser detectado o bloqueado. Si bien estas soluciones aún están en desarrollo, ilustran cómo la ingeniería está buscando maneras de encapsular las intenciones legales (el “solo para esto”) dentro de la infraestructura técnica. El principio de finalidad, al igual que el de minimización, recalca la necesidad de disciplina en el ciclo de vida de los datos: recoge solo lo necesario, úsalo solo para lo acordado. En la práctica empresarial de la era del “big data”, esto presenta tensiones (la posibilidad de reutilizar datos para fines novedosos es tentadora) pero precisamente por ello la ley insiste en poner frenos y requerir reconsideración (p. ej., obtener nuevo consentimiento, o demostrar que el nuevo uso es compatible porque es razonablemente esperable y no perjudicial para el usuario). En resumen, la limitación de la finalidad obliga a un diseño reflexivo de los flujos de datos, alineado con expectativas comunicadas al usuario.
Privacidad diferencial (Differential Privacy): Mientras los principios anteriores son de índole normativa-general, la privacidad diferencial es un método técnico concreto nacido en la comunidad de ciencias de la computación (en 2006) que ha ganado protagonismo recientemente como herramienta para conciliar análisis de datos con protección de la privacidad. En pocas palabras, es un marco matemático que permite cuantificar el riesgo de reidentificación o filtración de información personal cuando se publican o analizan datos agregados. A través de la introducción controlada de ruido aleatorio en las respuestas de consultas o en los resultados estadísticos, la privacidad diferencial garantiza que la contribución de cualquier individuo en un conjunto de datos sea indistinguible (hasta un parámetro definido) es decir, que alguien consultando la base de datos no pueda saber si un individuo específico está incluido o no, a nivel de certeza. ¿Por qué es relevante en un contexto jurídico? Porque muchas leyes (como el RGPD) establecen diferencias cruciales entre datos personales (que están protegidos) y datos anónimos (que quedan fuera del alcance de la ley). Sin embargo, la frontera entre personal y no personal se ha vuelto borrosa con las crecientes capacidades de reidentificar información supuestamente anonimizada. Aquí es donde entra la privacidad diferencial: ofrece un enfoque basado en garantías medibles para dicha anonimización. Huang y Zheng (2023) proponen usar privacidad diferencial para definir operativamente qué constituye dato “personal”, “seudonimizado” o “anónimo” en la práctica (ver referencia). Sostienen que mediante la elección de un presupuesto de privacidad adecuado (el parámetro ɛ en la terminología del modelo), un controlador de datos puede delinear las fronteras entre categorías de datos con un riesgo de identificación cuantificablemente acotado, proporcionando así una base técnica sólida para las definiciones legales. Implementado correctamente, esto permitiría a una organización publicar conjuntos de datos agregados o extraer conclusiones útiles (por ejemplo, patrones de tráfico urbano a partir de datos de móviles) sin comprometer la privacidad individual, o al menos manteniéndola dentro de umbrales acordados. Desde la perspectiva legal, un esquema así no solo aumenta la certeza y consistencia en la aplicación de las normas, sino que “inspira un nuevo modelo de interacción entre la ley y la tecnología”. Es decir, en lugar de verse como esferas aisladas, la regulación y la innovación técnica se integran: la ley pide anonimizar o minimizar, y la tecnología diferencial privacy ofrece una manera concreta y verificable de hacerlo, auditando el “riesgo de privacidad” de forma continua. Cabe mencionar que la privacidad diferencial ya ha trascendido el plano teórico: ha sido adoptada por compañías como Apple (en la recolección de datos de uso de ciertos servicios) y por instituciones públicas como la Oficina del Censo de EE.UU. en la publicación de estadísticas, lo cual ha generado incluso debates legales sobre hasta qué punto se puede considerar suficientemente anónimos esos datos alterados. Estos debates evidencian el naciente diálogo entre juristas y científicos de datos: comprender las suposiciones y limitaciones del modelo matemático, y a la vez ajustar los marcos normativos para reconocer estas técnicas como soluciones válidas. En conclusión, la privacidad diferencial ejemplifica cómo un avance puramente computacional puede dotar de nuevas herramientas al cumplimiento legal, reforzando el control del individuo (indirectamente, al garantizar que sus datos no “transpiran” información personal en análisis globales) y permitiendo usos beneficiosos de datos con menor riesgo.
En conjunto, Privacy by Design, minimización, limitación de finalidad y privacidad diferencial delinean una tendencia clara: mover la protección de la privacidad “hacia adentro” de los sistemas sociotécnicos. En lugar de confiar únicamente en reglas externas o en vigilantismo del usuario, se busca que los sistemas mismos tengan valores de privacidad incrustados en su ADN, sean mediante principios de diseño, arquitecturas limitantes o algoritmos sofisticados. Esto no elimina la necesidad de vigilancia regulatoria, al contrario, la complementa, ya que las autoridades y auditores ahora evalúan si las empresas están aplicando efectivamente estos principios (por ejemplo, se exige demostrar la conformidad con Privacy by Design mediante documentación de arquitectura, evaluaciones de impacto, etc.). Pero sí marca un camino hacia controles más preventivos y automáticos. Para los desarrolladores, abrazar estos conceptos implica también un cambio en su proceso: adoptar metodologías de desarrollo que integren evaluaciones de privacidad en cada sprint, familiarizarse con técnicas como privacidad diferencial o herramientas de anonimización, y colaborar con equipos legales de manera iterativa. Para los usuarios, idealmente, significará tener que confiar menos en sí mismos para gestionar cada detalle, y poder apoyarse más en garantías estructurales (como saber que un servicio recolecta lo mínimo y que sus datos agregados no revelarán nada identificable, etc.), sin perjuicio de mantener opciones de control manual cuando lo deseen.
Conclusiones
La protección de la privacidad digital exige un enfoque integral, que combine la fuerza normativa del derecho con la innovación y fineza de la ingeniería informática. La distinción enfatizada por Alashwali (privacidad entre usuarios vs. frente a instituciones) nos recuerda que la privacidad es un fenómeno multifacético: el usuario necesita mecanismos para controlar su exposición social, pero igualmente necesita garantías sobre el destino institucional de sus datos. Contrastar las perspectivas jurídicas y computacionales nos muestra que cada disciplina aporta piezas del mismo rompecabezas. El derecho aporta principios, derechos y un lenguaje común de protección (consentimiento, finalidad, minimización, responsabilidad proactiva), mientras que la computación aporta herramientas concretas para materializar esos principios (configuraciones de usuario, algoritmos de anonimización, protocolos de seguridad) y a la vez expone desafíos prácticos que la regulación debe tener en cuenta (p. ej., la dificultad de obtener consentimiento significativo en entornos saturados de interacciones).
Una de las conclusiones más importantes es que ninguna de las dos disciplinas, por sí sola, es suficiente para resolver el problema de la privacidad digital. Si nos apoyamos solo en la ley y el consentimiento, corremos el riesgo de sobrecargar al usuario y generar cumplimientos aparentes pero no efectivos (como vimos en las críticas al consentimiento). Si confiamos únicamente en la tecnología sin marco legal, es probable que las soluciones queden a discreción de actores privados con incentivos económicos que no siempre alinean con el interés del usuario, o que se implementen controles que el usuario no comprende ni ha validado democráticamente. La unión de ambas perspectivas, en cambio, puede producir sinergias poderosas: por ejemplo, el principio legal de “Privacy by Design” ha obligado a las organizaciones a repensar sus procesos internos, elevando la privacidad al nivel de exigencia de calidad de software, mientras que la investigación en HCI sobre usabilidad de las opciones de privacidad está influyendo en cómo los reguladores diseñan las normas secundarias o guías de cumplimiento (reconociendo, por ejemplo, la necesidad de estándares de interfaz de consentimiento más user-friendly).
Para los usuarios, un enfoque interdisciplinario bien ejecutado significaría una experiencia más segura sin requerir un doctorado en derecho o informática para protegerse: configuraciones más claras, menos bombardeo de solicitudes triviales de consentimiento y más garantías por defecto. También implicaría más transparencia y confianza: si veo que un producto está certificado o diseñado bajo principios de privacidad fuerte, puedo sentirme más cómodo compartiendo mis datos cuando sea necesario, sabiendo que habrá límites en su uso. Para los desarrolladores y diseñadores, la privacidad deja de ser un simple checkbox de cumplimiento al final, y se convierte en un requisito de diseño tan importante como la funcionalidad o la performance. Esto requiere nuevas competencias (entender conceptos legales básicos, colaborar con equipos de cumplimiento) pero también abre nuevas oportunidades profesionales, como lo evidencia el estudio de Grover donde los desarrolladores asumen un rol activo definiendo cómo implementar “el espíritu” de normas de privacidad en sus productos (ver referencia). En la práctica, veremos cada vez más figuras híbridas (ingenieros de privacidad, asesores techno-legales, etc.) integradas en equipos de desarrollo.
Para los responsables legales y reguladores, esta convergencia implica aprender a legislar y supervisar con mayor fineza técnica. Significa, por ejemplo, en lugar de imponer requisitos abstractos imposibles de medir, trabajar con la comunidad técnica para definir estándares alcanzables (por ejemplo, métricas de anonimización como el epsilon de privacidad diferencial, guías de UX para consentimiento, etc.) y fomentar la innovación responsable. También deberán adaptarse a evaluar sistemas complejos: auditar algoritmos, entender arquitecturas de datos, no solo leer políticas de privacidad en papel. Afortunadamente, la tendencia en los últimos cinco años sugiere que este diálogo se está estrechando. Como señalan Wong et al, aunque todavía es poco común que la investigación HCI incorpore directamente perspectivas legales, los casos que lo hacen demuestran el valor de conectar lo social, lo técnico y lo regulatorio para lograr impactos positivos tanto en diseño ético como en políticas públicas.
En conclusión, la privacidad digital en la era moderna no puede ser resguardada por una sola capa de control. Requiere un entramado de medidas legales y técnicas diseñadas conjuntamente, que se refuercen mutuamente. La tesis de los “dos tipos de controles” de Alashwali se ve enriquecida al considerar cómo ambos tipos se insertan en un contexto sociotécnico más amplio: por un lado, debemos asegurarnos de proveer a los individuos controles usables y comprensibles sobre su información (perspectiva de diseño centrado en el usuario); por otro, esos controles deben respaldarse con compromisos exigibles y salvaguardas ocultas que limiten lo que ocurre con los datos a nivel organizacional (perspectiva jurídica y de arquitectura interna). El ideal es un ecosistema donde el usuario recobre una sensación real de control (no ilusoria) porque las promesas legales se cumplen técnicamente y las herramientas técnicas responden a derechos reconocidos legalmente. Alcanzar ese ideal es un desafío continuo, que demandará investigación interdisciplinaria, educación de profesionales en ambos campos, e involucramiento de múltiples actores (academia, industria, reguladores y sociedad civil). Pero los avances recientes nos acercan a un futuro donde la privacidad, lejos de ser un concepto nostálgico, esté activamente protegida by design and by law (por diseño y por ley) en beneficio de todos.
Enlaces adicionales
Para poner en conocimiento del lector la importancia que supone preservar los datos, mantener la privacidad y proteger la identidad, proporciono una serie de enlaces que subrayan esta importancia:
Proyecto EUDIWAPRY (https://eudiwapry.com/)
Guia actualizada sobre IDENTIDAD DIGITAL, publicada por NIST
NIST Digital Identity Guidelines Evolve With Threat Landscape: The US National Institute of Standards and Technology updated its Digital Identity Guidelines to match current threats. The document detailed technical recommendations as well as suggestions for organizations. (enlace)
NIST’s final digital identity guidance could open door for new tech in government: The final version of long-awaited guidelines on digital identities incorporates new best practices to address mobile drivers licenses, passkeys, deepfakes, account recovery, and more. (enlace)
New NIST guide explains how to detect morphed images: Face morphing software can blend two people’s photos into one image, making it possible for someone to fool identity checks at buildings, airports, borders, and other secure places. These morphed images can trick face recognition systems into linking the photo to both people, allowing one person to pass as the other. (enlace)
Referencias:
- E. Alashwali. «Two Types of Data Privacy Controls: Differentiating privacy between a user and institutions and privacy between a user and other users.» Communications of the ACM, vol. 68, no. 8 (2025).
- K. Raynes-Goldie. «Aliases, creeping, and wall cleaning: Understanding privacy in the age of Facebook.» First Monday 15(1) (2010)
- R. Heyman, R. De Wolf, J. Pierson. «Evaluating social media privacy settings for personal and advertising purposes.» Info 16(4) (2014).
- L. Brandimarte, A. Acquisti, G. Loewenstein. «Misplaced confidences: Privacy and the control paradox.» Social Psychological and Personality Science 4(3) (2013).
- N. Bazarova, P. Masur. «Towards an integration of individualistic, networked, and institutional approaches to online disclosure and privacy in a networked ecology.» Current Opinion in Psychology 36 (2020).
- F.N. Roldán. «Los ejes centrales de la protección de datos: consentimiento y finalidad. Críticas y propuestas…», USFQ Law Review 8(1):175-202 (2021)
- C. Gray et al. «Dark Patterns and the Legal Requirements of Consent Banners: An Interaction Criticism Perspective.» Proc. CHI 2021 (May 2021)
- N. Bielova, C. Santos, M. Toth, D. Clifford (colaboradores en Gray et al. 2021). Resultados discutidos en INRIA sobre el impacto de dark patterns en consentimientos.
- N. Richards, W. Hartzog. «The Pathologies of Digital Consent.» Washington University Law Review 96(6):1461 (2019) .
- R. Grover. «Encoding Privacy: Sociotechnical Dynamics of Data Protection Compliance Work.» Proc. CHI 2024 (May 2024).
- R.Y. Wong et al. «Towards Creating Infrastructures for Values and Ethics Work in the Production of Software Technologies.» Preprint (2025), discutiendo la necesidad de integrar perspectivas legales en HCI.
- K. Rommetveit, N. van Dijk. «Privacy engineering and the techno-regulatory imaginary» (2022).
- T. Huang, S. Zheng. «Using Differential Privacy to Define Personal, Anonymous, and Pseudonymous Data.» IEEE Access vol.11 (2023).
- Reglamento (UE) 2016/679 (RGPD). Principios de protección de datos (Artículo 5) incluyendo minimización y finalidad.
- Utz, Nouwens, Matte et al. Estudios empíricos (2019-2020) sobre interfaces de consentimiento y cumplimiento RGPD.
Impacto de los modelos de lenguaje de gran tamaño: riesgos sistémicos y desafíos estructurales

Introducción
El auge reciente de los modelos de lenguaje de gran tamaño (LLM, por sus siglas en inglés) ha revolucionado la inteligencia artificial y el procesamiento del lenguaje natural. Tecnologías como GPT, BERT o LLaMA han demostrado tener capacidades sorprendentes para generar y resumir texto (recordemos que los LLM imitan), responder preguntas e “imitar” patrones de lenguaje humano. Sin embargo, este progreso rápido también ha puesto bajo el foco la relación entre la inteligencia artificial y la sostenibilidad. Detrás de cada interacción con un chatbot o de cada modelo entrenado, hay un consumo significativo de energía y recursos materiales. Por ello, está surgiendo un debate crítico sobre el impacto medioambiental de estos sistemas, más allá de su mera huella de carbono.
Mi intención con este post es la de explorar de forma crítica y estratégica cómo los LLM afectan no solo al clima, sino también a la cadena de valor tecnológica, a la industria del software y hasta a la seguridad nacional. Sin duda existen riesgos sistémicos y desafíos estructurales que estos modelos plantean en el medio y largo plazo.
Huella ambiental de los LLM
Entrenar y operar modelos LLM conlleva un enorme consumo energético. Tan solo el proceso de entrenamiento de un modelo del tamaño de GPT-3 puede requerir del orden de 10 GWh (gigavatios-hora), aproximadamente lo mismo que el consumo anual de más de 1.000 hogares. Pero el gasto no termina ahí: una vez desplegados, los LLM también demandan electricidad constante para responder a miles de millones de consultas (¿Os acordáis cuando se empezó a difundir la idea de tener la landing page de google en color negro “para consumir menos energía” o cuando se estimó el gasto que suponía cada consulta en google”?) . Se estima que servicios como ChatGPT, con cientos de millones de usuarios, puedan llegar a consumir nmás de 1 GWh al día sólo para la inferencia, es un consumo equivalente a 33.000 viviendas. Estas cifras ilustran que estamos ante cargas energéticas comparables a las de pequeñas ciudades o barrios enteros sosteniendo un solo modelo.
El impacto medioambiental directo de este consumo se refleja en emisiones de CO2 y otros indicadores. Por ejemplo, se calculó que el uso mensual agregado de ChatGPT podría estar generando más de 260.000 kilogramos de CO2, comparable a las emisiones de unos 260 vuelos transatlánticos de Nueva York a Londres. Este dato sobre el uso mensual de ChatGPT proviene, tal cual, de un estudio realizado por la empresa de hosting KnownHost, y fue divulgado por Morning Brew. El artículo original de Morning Brew, titulado “ChatGPT produces CO2 equivalent of over 250 transatlantic flights monthly, study finds”, explica que el cálculo proviene de estimaciones de uso de data centers con 164 millones de usuarios mensuales de ChatGPT, lo que arrojaba (en cálculos) unas emisiones totales de 260 930 kg de CO₂ al mes. Puedes consultar este artículo (a mi me impactó) en:
Además de la huella de carbono, los centros de datos que alojan LLM requieren refrigeración intensiva con agua y aire.
Cuando comparamos el sector de la IA con otras industrias intensivas en energía, el panorama resulta alarmante. El conjunto de los centros de datos del mundo (incluyendo los que ejecutan IA) ya representan entre un 2,5% y 3,7% de las emisiones globales de gases de efecto invernadero, superando incluso al sector de la aviación civil.
El auge de los LLM y otras tecnologías digitales podría duplicar la demanda eléctrica de aquí a los próximos años, según el International Energy Agency, con un tercio de ese aumento proveniente solo de centros de datos. De forma similar, las comparaciones con la industria de las criptomonedas han empezado a aparecer. Si bien el consumo total de Bitcoin y otras redes blockchain sigue siendo mayor en términos absolutos, las trayectorias de los LLM muestran una tendencia ascendente preocupante. Si la computación ya emplea cerca del 3% de la electricidad mundial, la proliferación de la IA podría triplicar esa cuota en la década actual.
Impacto en la cadena de valor tecnológica
El despliegue de LLM no solo acarrea costes ecológicos, sino también reconfiguraciones profundas en la cadena de valor tecnológica. Uno de los efectos más notables es la concentración extrema de recursos computacionales en manos de unos pocos actores. Entrenar un LLM puntero requiere infraestructura de última generación. Esto genera barreras de entrada casi insuperables para empresas emergentes, centros de investigación más pequeños o países con menos recursos: sin acceso a supercomputación y energía barata, resulta inviable competir en la carrera de los LLM.
A esta concentración de poder computacional se suman dependencias críticas de hardware y energía (como hemos visto). Los chips más avanzados para IA (GPUs de alta gama, TPUs, etc.) son costosos y distribuidos según relaciones comerciales o geopolíticas.
Esto implica que el progreso en IA está atado a la disponibilidad de componentes físicos (semiconductores avanzados) y a un suministro eléctrico confiable y asequible (que en España, ahí lo dejo…). Cualquier disrupción en esas cadenas podría ralentizar o paralizar el avance de los LLM, afectando a todos quienes dependan de ellos. Sin mencionar el menoscabo que se produce cuando (como ha pasado recientemente) cae el servicio de acceso a los LLM (con ChatGPT) y caen -por tanto- todas las cadenas de optimización y automatización de servicios que están adoptando las empresas (muchas veces sin considerar las consecuencias).
El efecto cascada en la cadena de valor también se manifiesta en la relación entre startups y grandes corporaciones. Ante la imposibilidad de construir modelos desde cero, muchos actores pequeños optan por utilizar APIs o modelos pre-entrenados provistos por las grandes empresas, reforzando la dependencia hacia estas últimas. Las autoridades de competencia han empezado a observar con preocupación esta dinámica, sospechando que las big tech podrían estar reforzando posiciones dominantes: controlan la infraestructura, el expertise y la monetización de la IA, asfixiando la competencia abierta.
En definitiva, los LLM plantean un reto estructural: ¿cómo democratizar el acceso a la IA avanzada cuando el costo de entrada es tan alto? La sostenibilidad, en este contexto, no es solo ambiental sino también económica y de ecosistema: un oligopolio tecnológico concentrado puede inhibir la innovación diversificada y dejar a muchas comunidades fuera de los beneficios (y de las decisiones) ligados a la IA.
Consecuencias para la industria del software
La influencia de los LLM se extiende al paradigma de desarrollo de software y al modelo de negocio en la industria tecnológica. De hecho, estas IA han demostrado una capacidad sin precedentes para comprender y generar código, llegando a asistir en tareas de diseño de software, programación automatizada y mantenimiento; algo que la literatura identifica ya como un cambio de paradigma en la ingeniería de software. Tradicionalmente, crear software implicaba escribir código fuente siguiendo lógicas predefinidas. Ahora, con la irrupción de modelos pre-entrenados, comienza a gestarse un nuevo enfoque: software + modelo. En lugar de programar cada función desde cero, los desarrolladores integran un LLM en sus aplicaciones para aprovechar sus capacidades de generación o análisis de lenguaje. Esto agiliza ciertas tareas y permite funcionalidades antes impensables, pero también plantea dependencias técnicas (y claro, ¿revelación de la lógica de negocio a quienes poseen la capacidad de dominar esos modelos?). Por ejemplo, una aplicación de asistencia al cliente (chatbots) puede construirse en torno a un modelo lingüístico: si dicho modelo deja de estar disponible (o encarece su API), el producto entero se resiente. Además, el know-how del desarrollador pasa de ser puramente programación a ser gestión de datos, ajuste de modelos (fine-tuning) y control de calidad de las respuestas de la IA, lo que supone un cambio de mentalidad en el ciclo de vida de desarrollo de software.
Otra preocupación es el riesgo de monocultivo tecnológico en la esfera del software. Si toda una industria adopta soluciones basadas en los mismos pocos modelos de lenguaje, existe la posibilidad de fallos correlacionados a gran escala. Muchos LLM comparten la misma filosofía de diseño y conjuntos de datos similares, lo que significa que un mismo sesgo o vulnerabilidad podría manifestarse simultáneamente en varios sistemas aparentemente independientes. Al igual que en la biología un monocultivo es susceptible a una plaga específica, en tecnología una homogeneidad excesiva podría ocasionar problemas sistémicos: desde errores generalizados de razonamiento hasta brechas de seguridad explotables de forma masiva. La robustez del ecosistema software podría disminuir si todos dependen de la misma “semilla” algorítmica.
Este riesgo conecta con la tensión latente entre la innovación abierta y la propiedad cerrada de los modelos. Durante décadas, la industria del software floreció gracias al código abierto y estándares compartidos, que permitieron a comunidades enteras colaborar y auditar herramientas críticas. En el mundo de los LLM, sin embargo, estamos viendo una tendencia contraria: los modelos más avanzados suelen ser propietarios, entrenados con datos y recursos privados, y funcionan como cajas negras cuya sintaxis interna nadie externo conoce. Esto trae eficacia y velocidad de avance, pero a costa de la transparencia y la reproducibilidad científica. Por otro lado, varios proyectos de código abierto (como modelos publicados por iniciativas académicas o cooperativas) buscan democratizar el acceso a estas tecnologías, aunque enfrentan limitaciones de escala. La disyuntiva es clara: ¿debería la base del software del futuro descansar en unos cuantos modelos opacos controlados corporativamente, o en una diversidad de modelos accesibles y auditables? La respuesta tendrá implicaciones de largo alcance para la seguridad, la confianza del usuario y la capacidad de innovación desde la periferia.
Implicaciones para la seguridad nacional
La carrera por los LLM también adquiere una dimensión geopolítica. En términos de seguridad nacional, los países están evaluando el rol de la IA como factor estratégico, comparable en importancia a los semiconductores o a las redes 5G en años recientes. Uno de los puntos críticos es la soberanía digital: si una nación depende exclusivamente de modelos de lenguaje alojados en infraestructuras extranjeras, su autonomía tecnológica se ve comprometida. Esto preocupa particularmente a la Unión Europea, que tras años pregonando el lema de “IA made in Europe”, reconoce que el control de las empresas estadounidenses sobre las plataformas digitales en Europa no ha hecho sino aumentar. La incapacidad de “mantenernos sobre nuestros propios pies” en el ámbito de la IA tendrá un precio alto y va a dejar a la UE vulnerable a intereses foráneos.
Las infraestructuras que soportan los LLM, grandes centros de datos, cables de telecomunicaciones, suministro eléctrico estable se están convirtiendo en activos críticos de seguridad. Al concentrarse muchas de estas instalaciones en ciertos países o bajo control de unas pocas empresas, surgen vulnerabilidades potenciales. Por ejemplo, una interrupción en la infraestructura de nube de un proveedor dominante podría impactar no solo a empresas, sino a servicios gubernamentales de otras naciones que la utilicen (y ya hemos tenido los dos avisos, primero el corte de suministro eléctrico en la península y luego la falta de servicio de chatGPT ). Asimismo, el enorme consumo energético de la IA puede convertirse en un talón de Aquiles: instalaciones que requieren decenas de megavatios podrían ser objetivos estratégicos en conflictos (os recomiendo consultar el manual de Tallinn), o verse afectadas por restricciones energéticas en tiempos de crisis. Incluso la explotación de datos sensibles es un flanco: si los modelos son entrenados o alojados en jurisdicciones con legislaciones distintas, el tratamiento de datos confidenciales (personales, empresariales o estatales) podría escaparse del control local.
En el tablero global, la IA generativa ya es vector de influencia geoestratégica. Quienes lideren en esta tecnología podrían obtener ventajas en inteligencia, ciberseguridad, economía y disuasión militar. De ahí que Estados Unidos y China estén inmersos en una auténtica carrera por el liderazgo en IA, arrastrando tras de sí a otras potencias y bloques regionales. El control de los insumos críticos (como los semiconductores avanzados necesarios para entrenar LLM, o las grandes reservas de datos) se equipara a una nueva versión de la carrera armamentística digital. Un ejemplo palpable es el bloqueo a la exportación de ciertos chips de alta gama hacia países rivales, justamente para limitar su capacidad de desarrollar IA militarmente avanzada. En comparación con sectores como el petróleo o la energía nuclear, la IA aún es incipiente en regulaciones internacionales, pero su creciente peso sugiere que pronto estará en las mesas de negociación diplomáticas. Las naciones tendrán que equilibrar la cooperación (para establecer estándares y evitar usos malignos de la IA) con la competición (para no quedarse atrás en capacidad tecnológica).
Retos estratégicos a medio y largo plazo
Frente a este panorama, emergen varios dilemas éticos y regulatorios que nuestras sociedades deberán afrontar. Por un lado, está la cuestión de la responsabilidad ambiental: ¿Deberían las empresas y laboratorios declarar el impacto ecológico de sus sistemas de IA de gran escala? En 2024, Salesforce propuso políticas para exigir que los proveedores de IA divulguen sus emisiones de carbono y la eficiencia energética de sus modelos, dentro de un marco de “IA sostenible”. Esta iniciativa reconoce que los LLM conllevan no solo beneficios económicos sino también riesgos ambientales considerables, y que la transparencia en este aspecto es crucial para una regulación adecuada.
Otro reto estratégico será impulsar alternativas más sostenibles y resilientes en el diseño de IA. Esto implica varias líneas de acción. Primero, desarrollar modelos más pequeños y especializados que logren resultados competitivos con una fracción de los recursos. La investigación en técnicas como la distilación de modelos, la cuantización o el entrenamiento multimodal eficiente busca precisamente hacer más con menos. Segundo, fomentar la eficiencia algorítmica: no siempre la solución es sumar más GPUs; de hecho, los avances algorítmicos han demostrado ser capaces de reducir enormemente las necesidades de cómputo para un mismo objetivo. Un análisis de OpenAI mostró que entre 2012 y 2019, gracias a mejores algoritmos, se consiguió entrenar modelos de visión con el mismo nivel de desempeño utilizando 44 veces menos cómputo que antes. Este tipo de mejoras “invisibles” al usuario final son las que podrían marcar la diferencia entre una IA insostenible y otra optimizada. Y tercero, está la apuesta por el edge computing o computación en el extremo: llevar ciertas capacidades de IA fuera de los macro centros de datos hacia dispositivos locales (desde smartphones hasta servidores pequeños in situ). Ya existen avances que permiten ejecutar modelos avanzados de lenguaje en hardware convencional con relativa eficiencia.
En conjunto, estos retos requieren no solo innovación tecnológica sino también voluntad política y colaboración multisectorial.
Se plantean preguntas difíciles: ¿Habrá que poner límites regulatorios al tamaño o consumo de los modelos? ¿Cómo asegurar que el progreso en IA no entre en contradicción con los compromisos climáticos globales? La ética de la IA ya no puede ignorar su dimensión medioambiental, así como las políticas tecnológicas nacionales deberán integrar la sostenibilidad como eje estratégico.
FrostyGoop: Análisis del Malware ICS y la sorpresa de encontar que Golang est en el Cibercrimen

Fuente de la imagen: https://www.nozominetworks.com/blog/protecting-against-frostygoop-bustleberm-malware (esta web también analiza Frosty Goop).
La especulación de las últimas semanas sobre los ataques a la industria y sobretodo a la infraestructura eléctrica (algo que no es nuevo) hace que revise el trabajo que estoy realizando en el análisis de Frosty Goop. Y durante este análisis me he encontrado con aspectos curiosos. El primero es el uso de Golang. Todo esto lo voy a desarrollar en este artículo.
Esta semana voy a impartir dos charlas técnicas sobre este malware en mi universidad y la semana que viene tendré el privilegio de asistir a la Universidad de Castilla-La Mancha, en el campus de Toledo para exponer estos avances.
La cuestión es: hay que tener en cuenta todo el sistema operacional en España (Europa por extensión) porque es muy vulnerable. Vamos al lío:
Contexto
FrostyGoop es un malware para sistemas de control industrial (ICS) identificado recientemente que apareció en 2024. A principios de ese año, fue utilizado para interrumpir el funcionamiento de una planta de calefacción en Leópolis, Ucrania, dejando sin calefacción a aproximadamente 600 apartamentos durante una ola de frío con temperaturas bajo cero. Este fue el primer caso conocido de malware que abusó directamente del protocolo Modbus/TCP (puerto 502) para enviar órdenes a dispositivos ICS.
A diferencia de los troyanos de acceso remoto (RAT) tradicionales, el “payload” de FrostyGoop consiste en una secuencia de comandos de lectura/escritura en registros Modbus, enviados a controladores lógicos programables (PLC) o unidades de control distribuido. Es probable que haya sido introducido a través de un dispositivo expuesto a Internet (lo más probable es que fueran router MikroTik ocn vulnerabilidades.
Una vez en un host Windows, el binario de FrostyGoop se ejecuta (normalmente mediante un archivo de configuración basado en JSON) para enviar comandos Modbus no autorizados a controladores de calefacción de la marca ENCO. Esto permitió a los atacantes modificar los valores de consigna y las lecturas de sensores, provocando fallos que interrumpieron el suministro de calefacción.
En la práctica, FrostyGoop no era una backdoor ni un worm, sino una herramienta utilizada bajo demanda. Los analistas creen que los operadores la ejecutaban manualmente o mediante scripts, utilizando archivos JSON preconfigurados.
En esencia, el malware lee y escribe secuencialmente registros específicos de PLC, y puede esperar un intervalo determinado entre operaciones. Los binarios de FrostyGoop no presentan cifrado ni empaquetamiento aparente; en cambio, su tamaño (alrededor de 4–6 MB) revela que son ejecutables de Go enlazados estáticamente. Este tamaño elevado es intencionado: muchos motores antivirus tienden a omitir, o a escanear solo parcialmente, archivos inusualmente grandes.
Paradójicamente, esta “hinchazón” beneficia a los atacantes. La mayoría del malware habitual pesa menos de 2 MB, por lo que un archivo mayor a 4 MB resulta llamativo; sin embargo, algunos motores de análisis simplemente lo omiten para conservar recursos.
FrostyGoop, al estar compilado de forma estática en Go, evita dependencias externas (como DLLs o archivos auxiliares de Python) y genera un binario de gran tamaño que puede eludir los análisis rápidos de los antivirus. Reconozco que me ha impactado.
Características
| Característica | Detalles |
|---|---|
| Plataforma | Windows (binario compilado en Go). |
| Lenguaje | Go (Golang) !!!! |
| Vector de entrada | Dispositivo ICS expuesto, probablemente un router MikroTik VPNFLIX bug comprometido. |
| Protocolo usado | Modbus/TCP (puerto 502) para control directo de PLCs. |
| Comunicación C2 | Ninguna tradicional – se ejecuta localmente mediante comandos o archivos JSON. |
| Configuración | Configurable mediante argumentos de línea de comandos o archivos JSON con listas de tareas. |
| Registro de actividad | Salida opcional a consola o archivo JSON. |
| Librerías utilizadas | Librerías Go de código abierto para Modbus, JSON y control de ejecución en cola. |
| Anti-análisis | Verificación del flag “BeingDebugged” en el PEB de Windows; sin DLLs externas. |
| Evasión | Binario de gran tamaño (~4–6 MB), lo cual evita algunos escaneos antivirus automáticos. |
Modus operandi y payload
El ejecutable de FrostyGoop se ejecuta en un sistema Windows comprometido que tenga conectividad de red con los equipos ICS. Acepta como entrada argumentos por línea de comandos o un archivo de configuración en formato JSON (mira la Tabla 1). El archivo JSON permite definir múltiples “bloques de ataque”, cada uno de los cuales especifica: el registro Modbus objetivo (tipo y dirección), la operación (lectura o escritura) y, de forma opcional, un valor. Un objeto JSON separado, denominado “Cycle”, define los parámetros de temporización (por ejemplo, el retardo entre comandos).
Por ejemplo, la muestra analizada contiene una “TaskList” con operaciones como la lectura de registros de entrada para medir el caudal, o la escritura en registros de control; y un bloque “Cycle” con una función de retardo entre comandos.
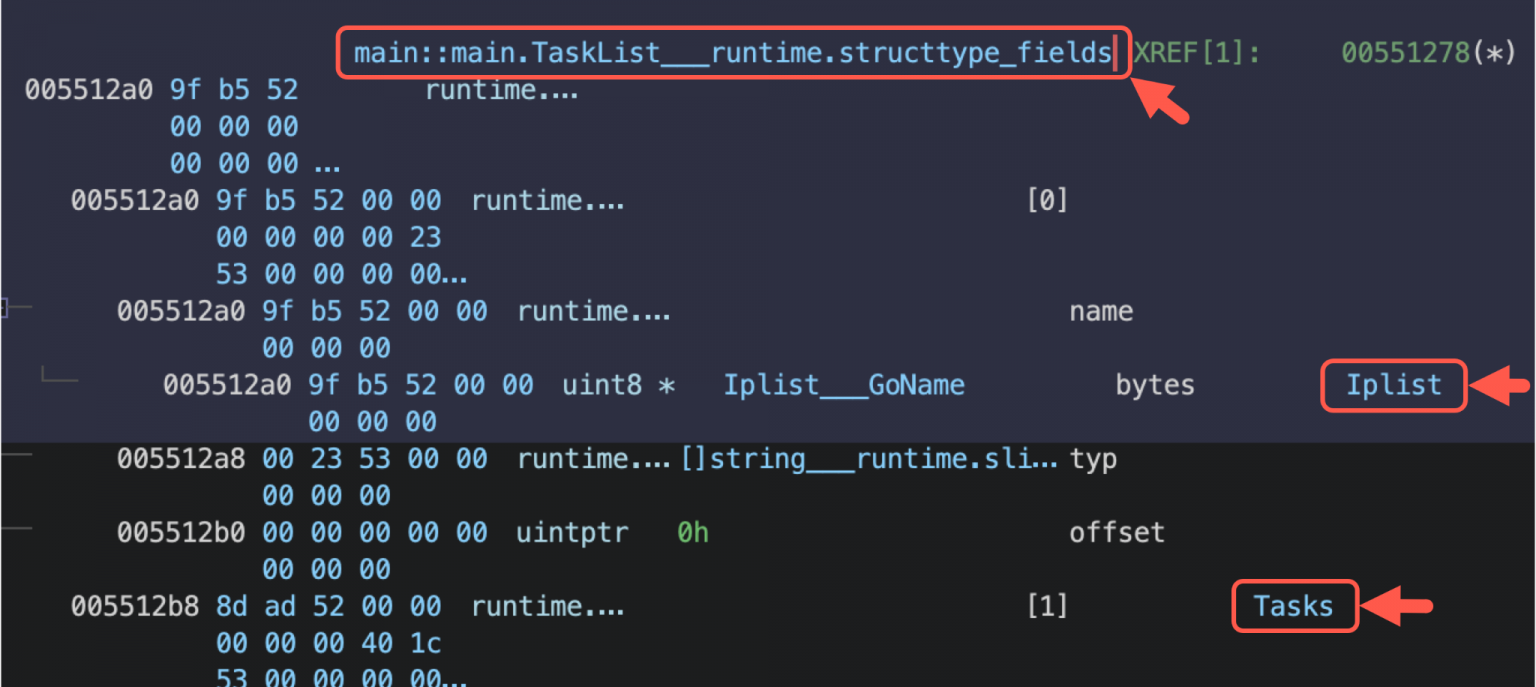
Fuente: https://unit42.paloaltonetworks.com/
Una vez lanzado, FrostyGoop abre una conexión TCP al PLC objetivo a través del puerto 502 y ejecuta comandos Modbus de lectura/escritura exactamente según lo especificado. En el incidente de Leópolis, los operadores lo usaron para enviar valores de control falsos a controladores de calefacción de la marca ENCO. Por ejemplo, pudieron haber escrito el valor 0 en las bobinas de “habilitación de bomba”, o alterado los valores de compensación de temperatura, provocando que las bombas se apagaran o que los sensores devolvieran datos erróneos.
Estos comandos Modbus no autorizados causaron fallos operativos —como bombas fuera de servicio o sensores que marcaban “0”—, lo que conllevó una interrupción del servicio de calefacción durante aproximadamente 48 horas, hasta que los comandos fueron detectados y reinicializados.
FrostyGoop ejecuta directamente los comandos, no depende de un canal clásico de command-and-control (C2) ni descarga instrucciones desde un servidor remoto. En su lugar, el atacante precarga las instrucciones (el payload) mediante el archivo JSON y simplemente ejecuta el binario. Esto evita tener que implantar FrostyGoop en cada sistema víctima o mantener una conexión persistente; los atacantes pueden emitir los comandos desde una máquina bajo su control con acceso a la red objetivo, lo que “elimina la necesidad de distribuir (sin ser detectado) el malware en activos dentro de la red atacada”.
Técnicas de evasión y anti-análisis
FrostyGoop presenta un nivel mínimo de ocultación más allá de su gran tamaño binario, que por otro lado le ayuda a pasar los controles. No está empaquetado ni ofuscado de forma compleja: en disco contiene cadenas de texto legibles (algunas provenientes de bibliotecas de código abierto y rutinas de registro de eventos). No obstante, incluye una técnica deliberada de anti-análisis. El malware realiza una comprobación para detectar si está en un entorno de análisis (esto evitaría su detonación ya que sería detectado) de depuración accediendo directamente a la estructura Process Environment Block (PEB) de Windows y leyendo el flag BeingDebugged,
En lugar de invocar la API estándar IsDebuggerPresent(), el código compilado en Go accede a bajo nivel a la estructura PEB y verifica el parámetro BeingDebugged. Si detecta que hay un depurador presente, abortará la ejecución o alterará su comportamiento.
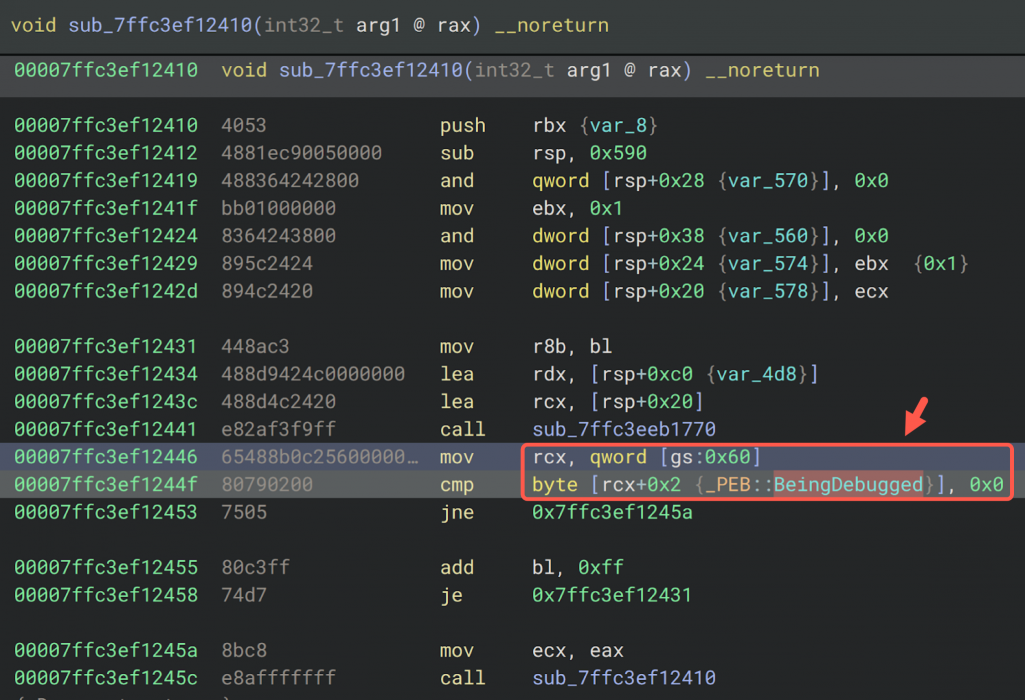
Esto indica que los desarrolladores del malware eran conscientes del uso de herramientas de análisis, e implementaron una verificación de bajo nivel para evitar puntos de interrupción o depuración en entornos virtualizados. Más allá de esto, la única “evasión” de FrostyGoop radica en su modelo de uso: como no establece comunicaciones «beacon» ni se inyecta en otros procesos (usando técnicas clásicas como le process hollowing, etc), las defensas tienen pocos elementos a los que aferrarse. Simplemente realiza lecturas y escrituras de registros a través de Modbus de una forma que, para un sistema OT, puede parecer tráfico de control legítimo —salvo porque los comandos no estaban autorizados.
En resumen, sus mecanismos de evasión se basan en:
Enlace estático: al no depender de bibliotecas dinámicas, evita anomalías de búsqueda de DLLs, aunque esto conlleva un archivo de gran tamaño que algunos motores antivirus omiten escanear.
Verificación PEB: una técnica de anti-depuración sigilosa que puede detectar intentos de análisis dinámico.
Uso de un protocolo ICS común: se camufla dentro del tráfico Modbus/TCP, que muchas redes industriales no supervisan de forma exhaustiva.
Cabe señalar que su estructura de código es legible como binario de Go, por lo que puede ser descompilado o analizado mediante ingeniería inversa (herramientas como Ghidra o IDA Pro ofrecen soporte para ejecutables en Go).De hecho, el uso de bibliotecas Go de código abierto específicas (para Modbus, JSON y gestión de colas) deja huellas características en la tabla de símbolos y en las cadenas del binario.
Impacto en el contexto industrial
El impacto inmediato de FrostyGoop fue una interrupción significativa de infraestructura crítica: unos 600 edificios de apartamentos en Leópolis quedaron sin calefacción central durante aproximadamente 48 horas en condiciones invernales bajo cero. La recuperación requirió que los operadores anularan manualmente los valores alterados en los PLC afectados y restablecieran los parámetros correctos. Es evidentemente un ataque de un Estado-Nación a ciudadanos.
En un sentido más amplio, FrostyGoop demuestra que las redes ICS modernas siguen siendo vulnerables al sabotaje remoto mediante malware. El vector de entrada no fue un correo de phishing ni una memoria USB infectada (como ocurrió en Irán), sino un dispositivo de red vulnerado (un router) que actuó como puente entre los entornos IT y OT. Una vez dentro de la red ICS, había escasa segmentación entre el router comprometido y los controladores de calefacción, lo que permitió al atacante encaminar directamente sus comandos hacia la zona de control.
Desde una perspectiva de ciberseguridad, FrostyGoop resulta alarmante por dos motivos:
(1) Hasta ahora, la mayoría del malware dirigido a sistemas industriales (como Stuxnet, BlackEnergy, Havex, CrashOverride, TRITON, Industroyer/Pipedream, etc.) se enfocaba en redes eléctricas o procesos industriales. Pero FrostyGoop muestra que también es posible manipular controles de calefacción remotos. De hecho, es el primer malware conocido que armó el protocolo Modbus/TCP como vector directo de control. Modbus es omnipresente en la industria (control de plantas, servicios públicos, sistemas de agua, etc.), y en 2024 se estimaba que había más de 46.000 dispositivos Modbus expuestos a Internet.
(2) FrostyGoop pone en evidencia los desafíos de proteger redes OT. Al utilizar tráfico estándar de ICS, el malware esquiva muchas defensas orientadas a IT. Como señalan los investigadores de SANS, enviar comandos Modbus desde fuera de la red “elimina la necesidad de instalar el malware en activos dentro de la red objetivo, evitando así su descubrimiento, análisis y análisis forense”. En la práctica, los atacantes solo necesitan acceso a la subred ICS, sin comprometer cada controlador o estación de trabajo. Este modo de ataque reduce la efectividad de las soluciones de seguridad en los terminales de las salas de control si el adversario ya ha logrado una posición en la red.
En un contexto más amplio, FrostyGoop representa otro punto en la creciente ciberconflictividad contra infraestructuras críticas. Su origen probablemente estatal (todos nos imaginamos el país dada su trayectoria de ataques al sector energético ucraniano) encaja con incidentes anteriores.
El hecho de que FrostyGoop ya esté documentado públicamente implica que cualquier red ICS que utilice Modbus está en riesgo. Las medidas clave de mitigación incluyen:
- Segmentar adecuadamente las redes ICS.
- Corregir vulnerabilidades en routers y cortafuegos expuestos.
- Monitorizar activamente el tráfico Modbus.
Golang (Go) en el desarrollo de malware: tendencias y comparativas
El uso de Go en el malware FrostyGoop no es un caso aislado; de hecho, los investigadores en ciberseguridad han documentado un incremento notable en el malware escrito en lenguajes modernos como Go. Entre mediados de 2021 y principios de 2024, muchos grupos de amenazas (APT) e incluso operadores de ransomware adoptaron Go/Golang como su lenguaje preferido. ¿Por qué? Diversos factores hacen que Go sea atractivo para los autores de malware:
Compilación multiplataforma
Go permite compilar un único código fuente para Windows, Linux, macOS, ARM, etc., sin o con mínimos cambios. Una única base de código puede compilarse para todos los principales sistemas operativos. Esto simplifica el desarrollo: el atacante puede escribir las herramientas una vez y desplegarlas en servidores, estaciones de trabajo, IoT, etc., sin tener que reescribirlas para cada sistema operativo. En cambio, un troyano en C++ debe requerir compilaciones separadas o incluso cambios en el código para cada plataforma. Asimismo, el uso de lenguajes como Python implica incluir intérpretes o usar herramientas como PyInstaller, que dejan artefactos reconocibles tras su desempaquetado. Los binarios en Go contienen todo el runtime y las bibliotecas necesarias dentro del propio ejecutable, sin necesidad de “pegamento” externo ni scripts sueltos.
Binario estático único
Go enlaza de forma estática su biblioteca estándar en el binario. Un simple “hola mundo” en Go puede compilarse en un ejecutable de varios megabytes. Para el malware, esto significa que un único archivo auto-contenido incluye todo lo necesario. A pesar del tamaño, los atacantes aprovechan esta característica ya que omo hemos dicho muchos antivirus evitan escanear archivos muy grandes como optimización de rendimiento.
Facilidad de uso como lenguaje de alto nivel
Go tiene una sintaxis moderna, clara y características integradas (como recolección de basura y primitivas de concurrencia) que aceleran el desarrollo. Los desarrolladores de malware, acostumbrados a C/C++, pueden encontrar en Go un lenguaje más sencillo y menos propenso a errores. Pueden aprovechar directamente bibliotecas del ecosistema Go (clientes HTTP, analizadores JSON, bibliotecas criptográficas, etc.). Go “ofrece muchas ventajas, pero también supone mayor carga para los analistas de malware”, lo que lo convierte en un arma de doble filo. Herramientas como GoBot2 y Veil demuestran que es factible escribir funciones complejas (botnets, generadores de payloads) en Go.
Herramientas y marcos de código abierto
La comunidad Go ha desarrollado numerosos marcos y herramientas, tanto para red teaming como para malware, que los atacantes pueden adaptar fácilmente. Por ejemplo:
- Veil (generador de payloads) incluyó cargas útiles en Go.
- HERCULES es un generador de shellcode en Go.
- GoBot2 es una botnet/C2 en Go con múltiples funciones.
Incluso herramientas de red teaming populares como Sliver (de Bishop Fox) están escritas en Go. Al usar estas herramientas, los atacantes obtienen funciones sofisticadas (canales cifrados, packers, módulos) con mínimo esfuerzo. De hecho, muchos grupos criminales ya prefieren Sliver en lugar del costoso Cobalt Strike, porque “Sliver está escrito en Go, [así que] sus implantes son multiplataforma” y “su personalización tiene una baja barrera de entrada”.
Evasión
Dado que Go aún es relativamente reciente en el ámbito del malware, muchas defensas de red y de endpoint carecen de detecciones especializadas para ejecutables en Go. Las firmas diseñadas para patrones Win32 PE o packers comunes pueden pasar por alto un EXE compilado en Go. Aunque los antivirus principales ya detectan muchas amenazas en Go (incluido FrostyGoop), existe una ventana de oportunidad durante la cual el malware nuevo en Go puede pasar desapercibido. Esto quedó demostrado en un informe de CrowdStrike que mostró un aumento del 80 % en muestras de malware en Go a mediados de 2021. Los atacantes detectaron que familias de amenazas comunes (como los cryptominers) explotaban con suficiente éxito esta brecha.
Ejemplos de malware y herramientas en Go:
| Nombre | Tipo/Uso | Características destacadas | Fuentes |
|---|---|---|---|
| FrostyGoop | Sabotaje ICS (energía/calor) | Inyector de payloads Modbus/TCP para PLCs; primer malware en usar Modbus con fines destructivos | Unit42, SANS |
| GoBot2 | Botnet / C2 | Botnet en Go con múltiples funciones (HTTP/S, persistencia, carga de archivos) | Unit42 |
| Veil | Generador de payloads | Framework para generar payloads ofuscados; incluye reverse shells en Go | Unit42 |
| HERCULES | Generador de payloads | Creador de reverse shells en Go vía TCP/HTTP/HTTPS; afirma evadir AV | Unit42 |
| CHAOS | Toolkit / RAT | Builder de reverse shells/RATs en Go (TCP, multicast); evade AV por ofuscación por defecto | LMNTRIX |
| Sliver | Framework Red Team / C2 | C2 de código abierto en Go. Implants para Windows, Linux y macOS. Usado como alternativa a Cobalt Strike | Microsoft, Cybereason |
| Agenda | Ransomware | Ransomware personalizable en Go para sectores como sanidad o educación | TrendMicro |
| Titan Stealer | Infostealer | Roba credenciales y claves; ejemplo de malware común en Go (eCrime) | CrowdStrike |
| Grabit / Sebi | RAT/C2 | Backdoor modular en Go (y Rust), usado por APT china (Earth Lusca) | Mandiant |
| Godzilla RAT | RAT / Loader | Downloader en Go activo y vendido en foros; nombre también usado por otros | CheckPoint |
Cada uno de estos ejemplos pone de manifiesto por qué se elige Go. Sliver y Veil muestran cómo incluso equipos de red teaming utilizan Go para crear implantes multiplataforma. GoBot2, CHAOS y HERCULES demuestran que es posible escribir botnets y shells completamente funcionales en Go. FrostyGoop y Agenda ilustran que tanto el sabotaje a infraestructuras industriales a nivel estatal como el ransomware moderno también están utilizando Go.
Es importante destacar que muchos de estos proyectos en Go eran de código abierto (en GitHub) antes de ser adoptados por actores criminales, lo que significa que los atacantes pueden inspeccionarlos y reutilizarlos con rapidez. En general, la preferencia por Golang proviene de su combinación de desarrollo rápido y flexibilidad operativa. Las herramientas que se compilan para múltiples plataformas a partir de un único código (“escribe una vez, ejecuta en cualquier parte”) reducen el esfuerzo, especialmente para atacantes que apuntan a sistemas diversos. Los binarios estáticos y auto-contenidos eliminan dependencias del runtime de Python o de Windows, facilitando una entrega más quirúrgica. Sus funcionalidades integradas (como goroutines para concurrencia, channels para coordinación y bibliotecas estándar completas) hacen que los desarrolladores no necesiten integrar muchas librerías de terceros.
Como contrapartida, quienes trabajamos en defensa nos enfretamos a nuevos desafíos: las heurísticas tradicionales (como las anomalías en la importación de DLLs) no son ya muy útiles, y las bases de datos de firmas van muy por detrás frente a las amenazas nuevas escritas en Go.
La creciente lista de malware basado en Go confirma esta tendencia: desde cryptominers hasta RATs, ICS dirigidos y ransomware, los actores de amenazas están aprovechando las ventajas de Go. Por tanto, debemos actualizar los sistemas de detección y análisis en consecuencia: necesitamos dotarnos de herramientas especializadas para desempaquetar e inspeccionar binarios en Go, monitorizar ejecutables grandes sospechosos y además, poder detectar comportamiento anómalo en protocolos de red atípicos (como tráfico Modbus no autorizado).
Analistas de Información: defensa de Europa
En un esfuerzo conjunto, bajo el amparo de agencias de inteligencia financiadas por Europa y la Universidad de Almería, estamos creando un itinerario formativo para capacitar al personal técnico en el rol de Analistas de Información en toda Europa. Nuestro objetivo es reforzar la defensa de Europa. Tras asistir a un curso intensivo sobre geopolítica y amenazas, los estudiantes seleccionados serán formados por nosotros en Italia, siguiendo esta planificación. Los datos sensibles han sido ocultados por razones de seguridad.