Se bienvenido a estas tierras digitales...
...especialmente si eres un molino....
La Inteligencia Artificial y su Impacto en el Bienestar y el Aprendizaje de los Estudiantes Universitarios
Descarga el artículo «Harnessing Machine Learning and Generative AI: A New Era in Online Tutoring Systems» ya que es un trabajo publicado en Open Access y por tanto, puede accederse, desde la editorial, libremente.

De la lectura de este artículo («Harnessing Machine Learning and Generative AI: A New Era in Online Tutoring Systems») y de este otro (que al no ser Open Access no puedo proporcionar acceso al mismo, pero que se titula «Understanding the Role of AI in Helping University Students Manage Their Psychological Wellbeing»), hoy, como vengo haciendo desde hace poco expreso mi opinión.
Hace tiempo que quería integrar en el sistema de aula virtual de la Universidad de Almería un sistema que reorganizase los contenidos de acuerdo a la capacidad de resolver tareas demostrada por los estudiantes (especialmente de primer curso). Para este efecto quería usar un software de resolución de tareas que explota la memoria de trabajo y la memoria espacial. Con este software ( que podéis ver y descargar aquí -si lo usas, por favor, acredita su autoría) se extraen parámetros que pueden determinar una estrategia u otra a la hora de distribuir tareas o incluso de liberar el contenido.
Estos dos artículos, que hoy comento aquí, tratan de favorecer la experiencia académica de estudiantes, en particular, universitarios. Porque, no lo vamos a ocultar, la Universidad forma parte del ciclo educativo más exigente. La maquinaria universitaria debe, por tanto, ser consciente del estrés y ansiedad que puede generar en los estudiantes y además ser consciente de que re-pensar la forma de relacionarse con el estudiante (habilitar diferentes tracks educativos en función del interés, habilidades, etc del estudiante).
En el contexto universitario, los estudiantes enfrentan desafíos significativos relacionados tanto con su bienestar mental como con el rendimiento académico. La Inteligencia Artificial (IA), y en particular los Modelos de Lenguaje Grande (LLMs), están comenzando a desempeñar un papel crucial en acercarse a la leviatánica tarea de abordar estas áreas, proporcionando soluciones innovadoras en la gestión de la salud mental (Understanding the Role of AI in Helping University Students Manage Their Psychological Wellbeing) y en el apoyo educativo personalizado (Harnessing Machine Learning and Generative AI: A New Era in Online Tutoring Systems). Honestamente, tratar de influir en personas con depresión, ansiedad o pensamientos suicidas a través de la IA Generativa me parece un atrevimiento. Pues no sólo no se conoce a priori (tampoco se puede predecir) el avance de la conversación ni las consecuencias que en la psique pueda afectar. ¿Hay responsables en este asunto?
Hay tres frases extraídas literalmente de estos dos artículos que generan cierta inquietud:
«They possess the capability to process extensive data on students’ behaviors,schedules, and emotional states»
En referencia a los datos que deben procesar, se interpreta el estado emocional, cuando queda patente que las IA es incapaz de empatizar ni siquiera de detectar estado de ánimo. Esto ya de por si revela, quizá, lo inapropiado de usar el ML y la IA Generativa para «todo». Hay barreras que no se deberían traspasar con tanta ligereza.
«While LLMs can process emotions expressed in text, their inability to fully understand human emotions inherently limits their therapeutic applicability.»
Pues esto es consecuencia directa de la primera frase. No son útiles para asuntos terapeuticos. Afortunadamente, en Europa, el uso de la IA tiene niveles de riesgo que limitan su aplicación. A pesar de que haya generadores de contenido (podcasters, etc) que vean esto un handicap para el desarrollo empresarial (y me refiero a la normativa europea).
«These challenges stem largely from the limitations of their algorithms, which often fail to capture the intricacies of human learning, and from the intensive demands placed on instructional designers to manually craft workflows for every conceivable teaching scenario.»
Somos incapaces de comprender muchas de las respuestas que ofrece la IA (y más de entender cómo se ha llegado a ellas). A esto se le suma la incapacidad de que un algoritmo mimetice o sintetice la lógica que esconde el aprendizaje de cada una de las personas.
Bienestar Psicológico de los Estudiantes
El entorno académico universitario es (como he dicho antes) tanto un espacio de crecimiento como de considerable presión. Los estudiantes enfrentan situaciones que afectan su bienestar psicológico: retos y tareas académicas, inseguridades sobre su futuro profesional y problemas de relaciones personales (se que es un tópico, pero están en la edad, no es la primera vez que en clase un estudiante refiere como excusa situaciones inestables domésticas y/o emocionales). Estudios recientes han revelado que más del 60% de los estudiantes universitarios cumplen con criterios de al menos un problema de salud mental, con un preocupante 15% que ha considerado seriamente el suicidio (este dato tan preocupante lo publica Mayo Clinic Health System en un artículo titulado College students and depression: A guide for parents. (con fecha 7 Julio 7, 2024) y se puede consultar en este enlace).
Aquí es donde este artículo invita a que pensemos que la IA emerge como un soporte esencial. Todo el artículo se apoya en el programa Small Steps SMS, que utiliza IA para ofrecer mensajes interactivos que ayudan a los estudiantes a gestionar síntomas de depresión y ansiedad. Realmente usa técnicas de ML (que lo hace menos efectivo) pero los mensajes son aportados por expertos y por la IA.
Este programa, según el artículo, ha mostrado un impacto positivo al reducir los síntomas de estos trastornos, gracias a su capacidad para personalizar mensajes que abordan los desafíos emocionales diarios de los estudiantes. Las historias personalizadas que se generan a partir de modelos como GPT-4 ayudan a los estudiantes a reflexionar sobre sus propios problemas, promoviendo una visión realista y positiva de sus desafíos y facilitando estrategias de afrontamiento. Pero sigo pensando en que todo es smoke, es decir, publicar por publicar. El peligro de que no veamos que la IA está germinando como la semilla de una futura burbuja (como ocurrió con las .COM). ¿Cómo que es capaz de abordar los desafíos emocionales? ¿Con mensajes? Una persona en un estado crítico no responde a mensajes de una aplicación.
Además, continúan aseverando que un aspecto clave de esta implementación de IA es su capacidad para adaptarse al contexto emocional y temporal de cada usuario, enviando mensajes de apoyo en los momentos más apropiados. Estas herramientas no solo ofrecen acompañamiento emocional, sino que promueven la independencia al facilitar el autoconocimiento y la reflexión sobre situaciones cotidianas.
No puedo creer que esto se haya publicado en ACM. Puedo entender que un sistema de tutorización o de gestión de tareas pueda evitar situaciones de estrés a través de la reducción en la procrastinación (por esto busqué el segundo artículo de esta crítica)… porque no creo que un sistema de mensajes de IA sea capaz de ajustarse al «contexto emocional y temporal» de nadie.
Mejora del Aprendizaje a través de la Tutoría Personalizada con IA
En el ámbito académico, y esta es la segunda derivada que quería comenzar a contrastar, los sistemas de tutoría inteligente (intelligent tutoring systems: ITS en adelante) han revolucionado el aprendizaje, ofreciendo experiencias educativas personalizadas que antes solo podían lograrse a través de tutores humanos. Sin embargo, las limitaciones de los ITS han sido notables, especialmente al intentar entender y adaptarse a las necesidades individuales de cada estudiante. La integración de IA generativa y machine learning está cambiando este panorama.
Un ejemplo destacado es el sistema Ruffle&Riley (no lo he encontrado, tan sólo este artículo y otro en arXiv, asi que no he podido probarlo), que emplea modelos de lenguaje como GPT-4 para crear un entorno de aprendizaje conversacional. En este sistema, los estudiantes (según el artículo) interactúan con dos agentes virtuales, Ruffle (un estudiante) y Riley (un profesor), en una experiencia de “enseñanza colaborativa” donde el propio estudiante explica los temas, reforzando su comprensión. Esta metodología no solo fomenta la participación activa, sino que también permite que el sistema identifique y corrija errores de concepto en tiempo real.
Además, la IA en los ITS permite ajustar el nivel de dificultad de las tareas en función del conocimiento y el progreso del estudiante, siguiendo principios como el de “aprendizaje por dominio”, que asegura que el estudiante domine un concepto antes de pasar al siguiente. Estos sistemas también ofrecen retroalimentación inmediata, permitiendo a los estudiantes corregir errores y avanzar de manera eficiente. Este enfoque adaptativo mejora la retención y el rendimiento, mientras que el uso de modelos de aprendizaje supervisado y refuerzo permite que los ITS ajusten sus estrategias pedagógicas continuamente en función de los datos de interacción del estudiante.
¿Qué es lo que termino pensando sobre esto?
La implementación de IA en la educación (si es posible) y en el bienestar de los estudiantes universitarios (si es posible si hablamos de bienestar porque la usan como planificador, generador de recursos, etc pero no como sistema que le permita lidiar con sus diatribas emocionales o sus problemas de salud mental) promete un cambio de paradigma, proporcionando un dudoso soporte emocional y un posible y creíble soporte académico de manera continua y personalizada. Sin embargo, es esencial un marco ético que proteja la privacidad y seguridad de los estudiantes.
La IA debe ser una herramienta de acompañamiento, diseñada para integrarse respetuosamente en la vida académica, evitando la dependencia y promoviendo el desarrollo de habilidades de autogestión y resolución de problemas.
Cuando los LLM decidan por nosotros…

Estos días he leído varios papers, pero hay un artículo (dos realmente) que refleja lo que siempre he dicho y es la debilidad -por ahora- de los modelos de Inteligencia Artificial Generativa. El artículo en cuestión es : GPTs and Hallucination Why do large language models hallucinate? (sus autores son Jim Waldo y Soline Boussard). Bueno, y ahí se puede medio dejar tranquila la cuestión, hasta que uno llega a un artículo como este: Do I Have a Say In This, or Has ChatGPT Already Decided for Me? It’s not just about LLMs, it’s about us too. (autor: Aadarsh Padiyath). Ay, amigo. Esto es diferente. Cuando la gente se apoya, sin reservas, sobre la IA Generativa, confía ciegamente en ella sin sospechar de lo que la sustenta.
De manera muy burda podríamos comparar esto con la precisión del punto flotante, o la coma fija -también denominada notación cientifica-, que estoy seguro que todos la hemos experimentado en el colegio o instituto. Cuando nos explican que cualquier valor puede expresarse de manera «manejable» (por ejemplo, en base 10, 0.00000000003 puede expresarse como 3×10^10) nos dan una herramienta potentísima, podemos manejar números muy grandes y números muy pequeños, juntos. Es más, podemos manejarlos. Que ya es un mérito. Nuestra percepción es esa. Hasta que los tratamos computacionalmente. En este caso, nos enfrentamos (quizá sea un sesgo codificado) a la forma en la que se representa esto en un sistema computacional: el IEEE-754. Y claro, éste se apoya en un sistema físico con limitaciones (tamaño de los registros internos del procesador, etc). Y ahora resulta que la operación con aritmética flotante NO es precisa. No. No lo es. Y cuanto más grande queremos que sea el número representado (mayor exponente) menos precisión alcanzo. Y al revés, cuanto más diminuto quiero que sea el número a representar, menos precisión alcanzo. Y claro, la precisión de nuestra realidad colisiona con la precisión que nos da un «ordenador».
Pues con los modelos, pasa igual. Es imposible erradicar el sesgo. No. No se puede. En los últimos años, los modelos de lenguaje grandes (LLM) como ChatGPT han cambiado por completo la forma en que interactuamos con la tecnología. Ahora, podemos automatizar tareas, crear contenido, e incluso recibir «ayuda» en decisiones importantes (uy, uy, que se pone caliente la cosa). Su habilidad para generar respuestas coherentes (no siempre) y con sentido casi nos hace sentir que estos modelos entienden nuestras necesidades y hasta casi que entienden lo que pensamos y no le decimos. Pero si miramos más de cerca, vemos que estos modelos también pueden “flipar”: producir respuestas que parecen correctas pero en realidad son falsas o no tienen ninguna base. Recuerdo al lector el ejemplo del IEEE-754. En estos casos, la situación es preocupante, sobre todo cuando se empiezan a usar en aplicaciones que afectan a decisiones importantes.
Por otro lado, hay otra preocupación creciente: la idea de «determinismo tecnológico», de la que habla Aadarsh Padiyath. Esta visión nos hace creer que somos meros receptores en este mundo «dominado» -o cuyo control ha sido cedido por nosotros- por la IA, adaptándonos a lo que sea que estas aplicaciones decidan hacer (esto me hace parafrasear a Noam Chomsky y su profecía sobre la lapidación del pensamiento crítico con el uso de redes sociales y en particular aquellas que limitan la expresión a 140 caracteres -por aquel entonces- como pasa con X -otrora twitter-). Esto es especialmente problemático en áreas -os podéis imaginar- como la educación y la toma de decisiones, donde la autonomía y el pensamiento crítico -que ya está bastante socavado- son clave. Si no tenemos cuidado, podríamos ceder sin querer el control sobre nuestras elecciones a estas herramientas de IA, creyendo que son infalibles o que su uso es inevitable. Dejo para otro post el asunto del control de opinión, deliberado, por ciertos modelos públicos. Que eso, también, tiene miga.
En su artículo, Waldo y Boussard destacan que los LLM funcionan a partir de probabilidades estadísticas (si, así es, la IA es básicamente un campo donde se aúnan redes neuronales y estadística -se que esto me va a traer críticas, pero entended que es una percepción personal-), no de conocimiento real. En lugar de saber algo de verdad, producen respuestas basadas en las palabras que tienen más probabilidades de aparecer juntas en sus datos de entrenamiento. Así, cuando se enfrentan a temas poco populares o polémicos, donde los datos son escasos, pueden (y lo hacen, y con mucha frecuencia) meter la pata. Esto plantea una pregunta importante: ¿hasta qué punto deberíamos confiar en las respuestas de la IA, especialmente cuando sus «fumadas» pueden desinformarnos o dar una visión sesgada (¿os he dicho ya que el sesgo es imposible de eliminar?)?
Por otro lado, y volviendo a Padiyath cuestiona (si, yo también) la idea de que estas herramientas de IA son imprescindibles. Su investigación muestra que los usuarios, sobre todo estudiantes, deciden cómo y cuándo interactuar con ellas según sus propias necesidades y objetivos. En lugar de aceptar sin más cada sugerencia de ChatGPT, los estudiantes ponen límites y usan la IA solo cuando les conviene (um, no se yo si estoy de acuerdo con este postulado de Padiyath, ya que a mi en clase me dicen «lo he buscado en chatGPT» -esto da para otro post-), especialmente en situaciones donde lo que realmente importa es entender profundamente el material. Padiyath sugiere que debemos ver estas herramientas como herramientas ajustables, no como reemplazos inevitables, reforzando así nuestra capacidad de decidir cómo y cuándo usarlas.
Nuestra relación con la IA necesita equilibrio. Por un lado, debemos estar atentos a los casos de “alucinaciones” y saber identificar (y esto implica un alto grado de especialización en cualquier campo del conocimiento donde se esté aplicando la IA) cuando el contenido generado por IA puede desviarnos. Y por otro, debemos adoptar una mentalidad que vea estas tecnologías como herramientas de apoyo, no como sustitutos del juicio humano. Así, podremos conservar nuestra autonomía en este ecosistema digital, integrando —o incluso rechazando— estas herramientas según nuestros valores.
Es inevitable ocultar que los LLM se integran cada vez más en nuestro día a día, por tanto es crucial recordar que tenemos una opción. En lugar de dejar que la IA decida por nosotros, deberíamos definir activamente cómo nos relacionamos con estas tecnologías para que reflejen nuestras necesidades, valores y aspiraciones reales. La «Super-Inteligencia» está todavía muy lejos.
La última barrera de nuestra privacidad.
En un mundo donde la tecnología avanza a pasos agigantados, el uso de inteligencia artificial (IA) para «mejorar» la identificación biométrica, especialmente en huellas dactilares y reconocimiento facial, está revolucionando la seguridad (de los estados). Pero esta tendencia plantea preguntas cruciales sobre la privacidad y la vigilancia, temas que deberían preocuparnos profundamente. Sobre todo teniendo en cuenta que no cuentan -estos métodos- en la mayoría de las ocasiones con nuestro consentimiento.

Los avances permiten a los sistemas encontrar coincidencias en patrones de huellas, e incluso identificar rasgos específicos dentro de la estructura de las huellas o los rostros. Este nivel de precisión podría ser útil para acceder a cuentas bancarias o atravesar fronteras, pero también representa una amenaza real para la privacidad.

La preocupación radica en la forma en que la IA maneja nuestra identidad biométrica. Las redes neuronales y otros sistemas de IA han demostrado mejorar significativamente en el reconocimiento de imágenes gracias a su capacidad para analizar grandes volúmenes de datos. Sin embargo, en la práctica, estos sistemas no son perfectos y enfrentan limitaciones, como la dificultad de identificar correctamente huellas parciales o rostros bajo condiciones no ideales. Aun así, el impacto es inquietante cuando recordamos que los algoritmos no siempre revelan en qué características basan sus decisiones, lo que hace difícil comprender cuándo ocurren errores o sesgos.
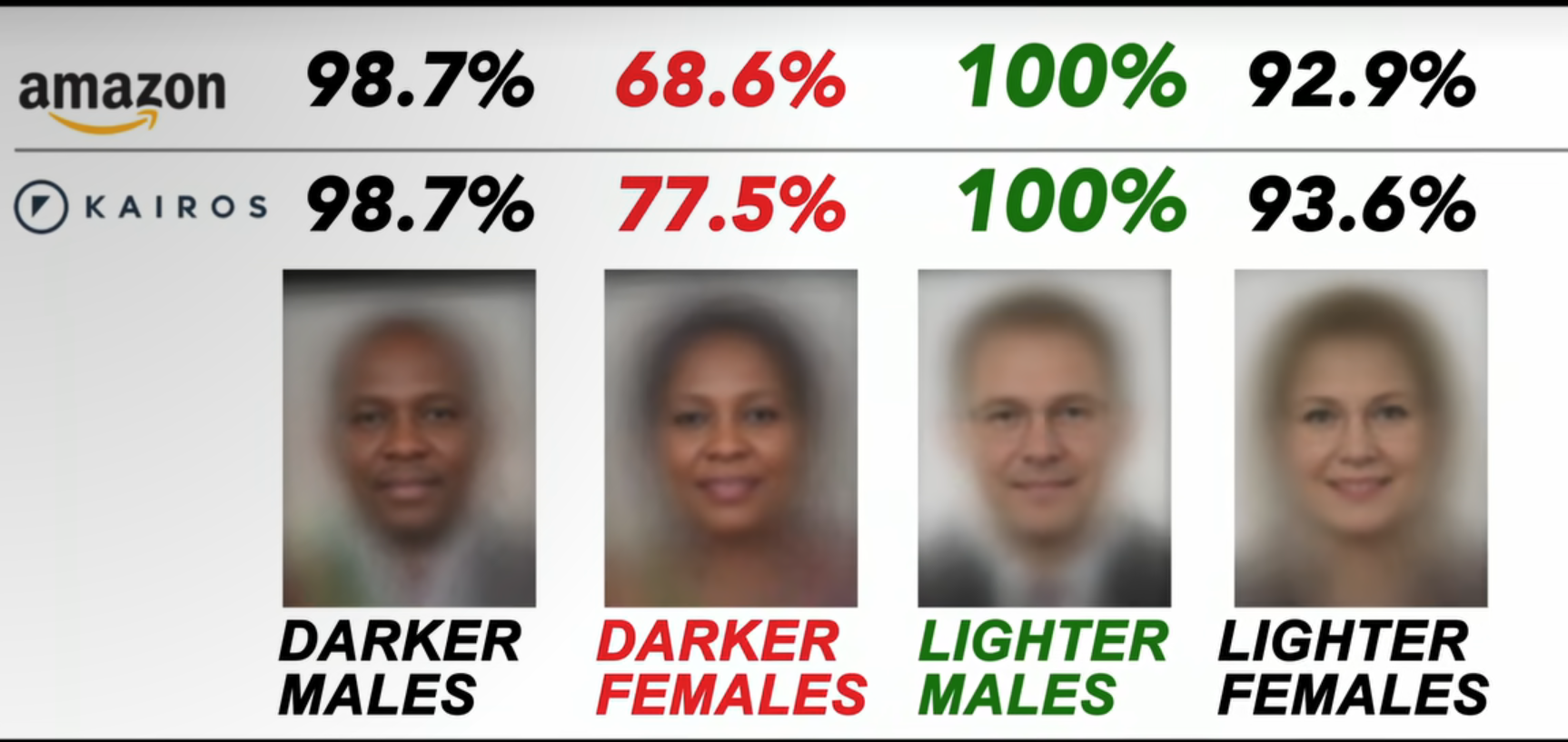
Se puede leer más sobre el problema del sesgo codificado en este artículo ( https://www.media.mit.edu/articles/facial-recognition-software-is-biased-towards-white-men-researcher-finds/ )
La Última Frontera de la Privacidad
La cuestión de la privacidad va mucho más allá de un simple fallo técnico. La cara y las huellas dactilares son, en muchos sentidos, la última barrera de nuestra intimidad. Una huella o un escaneo facial no es una simple contraseña que podamos cambiar; estos datos, una vez registrados y potencialmente mal utilizados, nos exponen de manera irreversible. Si la IA se convierte en un recurso fiable para sistemas de seguridad, estamos cediendo el control de nuestra identidad más allá de nuestro alcance.
Además, surge el problema de quién define los umbrales de seguridad en estos sistemas. Para que una tecnología sea conveniente en aplicaciones de bajo riesgo (como desbloquear un teléfono), los desarrolladores permiten ciertos márgenes de error. Sin embargo, para aplicaciones de alto riesgo, como el acceso a información sensible o situaciones judiciales, estos márgenes se reducen drásticamente, aunque los errores siguen existiendo. A esto se suma el potencial de un uso sesgado o incluso discriminatorio de estas tecnologías, como ya se ha documentado en ciertos sistemas de reconocimiento facial.
¿Qué Nos Espera?
Estos avances tecnológicos dejan entrever una realidad que todos deberíamos considerar críticamente. La IA no está lista para decidir sola si alguien ha cometido un crimen o para realizar un seguimiento total de nuestra identidad en cualquier contexto. Los errores pueden llevar a la detención de inocentes, o al uso indebido de nuestra información biométrica, y debemos preguntarnos si el beneficio que esto aporta justifica los riesgos.
En un mundo donde la línea entre seguridad y privacidad se difumina cada vez más, es esencial que cuestionemos hacia dónde nos lleva esta tecnología. Si bien los avances de la IA en biometría parecen emocionantes, necesitamos proteger la privacidad de nuestras características físicas con una visión ética que ponga a las personas por encima de la eficiencia tecnológica.
El aspecto más relevante podemos considerar que es el dilema entre precisión tecnológica y privacidad individual en el uso de IA para identificación biométrica. Aunque la inteligencia artificial mejora la precisión en la identificación de huellas dactilares y rostros, facilitando el acceso seguro y rápido en ciertas aplicaciones, también plantea serios desafíos en cuanto a la privacidad y los posibles errores.
Este dilema se agrava debido a la opacidad de los modelos de IA, ya que no siempre está claro en qué características basan sus decisiones. Esto implica que, aunque el sistema pueda ser útil en aplicaciones cotidianas, aún existen riesgos significativos cuando se utiliza en contextos críticos, como la aplicación de la ley. Un error o un sesgo en estos sistemas podría tener consecuencias devastadoras, como identificar erróneamente a personas inocentes o permitir accesos indebidos.
Es crucial analizar el equilibrio entre los beneficios de la IA en biometría y las amenazas a la privacidad, donde las decisiones éticas sobre el uso de esta tecnología resultan fundamentales.
De “Enemigos” a Aliados: Un Nuevo Enfoque en la Ciberseguridad Centrada en las Personas
Recientemente he leído el artículo publicado en Communications of the ACM, titulado : «Human-
Centered Cybersecurity Revisited: From Enemies to Partners»
Y os digo que me ha impactado. Es interesante porque estoy dirigiendo un TFM (Trabajo Fin de Master) junto con una persona de la politihogskolen (politihogskolen.no) donde analizamos el impacto del usuario dentro de la organización. Es cierto que la ciberseguridad ha evolucionado como una disciplina fundamental para proteger nuestra información y privacidad en un mundo cada vez más digitalizado. Sin embargo, una idea que aún prevalece (y que motiva el TFM) es que el «eslabón débil» en la seguridad son los propios usuarios. Los sistemas suelen diseñarse con el propósito de limitar los errores humanos, implementando políticas restrictivas o mecanismos de automatización, y asignando a los usuarios un rol pasivo o de “cumplimiento forzado”. ¿Es esta la mejor manera de abordar la ciberseguridad? Por lo menos es la que conocemos hasta la fecha.
Pero el artículo de Communications of the ACM cuestiona este enfoque. En él, los autores argumentan que en lugar de ver a los humanos como “enemigos” o posibles fuentes de error, tendríamos que considerar un nuevo paradigma: los usuarios como socios activos en la seguridad. ¿Queeeeé?
Esta perspectiva plantea que, si bien los errores humanos son una realidad, también lo son las capacidades únicas que los usuarios pueden aportar: creatividad, adaptabilidad y motivación intrínseca. Estos atributos pueden hacer que los usuarios sean agentes muy poderosos en la detección y mitigación de amenazas.
¿Por qué los enfoques tradicionales fallan?
El enfoque restrictivo de la ciberseguridad ha intentado limitar el papel de los usuarios. Las medidas como las políticas estrictas de contraseñas y la prohibición de uso de dispositivos externos son comunes, pero con frecuencia generan frustración. Los usuarios buscan atajos para lidiar con estas restricciones, como el uso de contraseñas simples o el almacenamiento de información de forma no segura. A pesar de las buenas intenciones, estos enfoques pueden ser contraproducentes. De hecho suelen ser vectores de ataque muy comunes.
Algunos han propuesto enfoques «considerativos» que intentan hacer las tecnologías de seguridad más «usables» y accesibles, comprendiendo mejor las limitaciones humanas. Sin embargo, la mayoría de estos métodos todavía mantienen a los usuarios como una fuente potencial de error, ignorando la posibilidad de que contribuyan activamente a la seguridad.
El enfoque habilitador: Convertir a los usuarios en aliados
En el artículo se sugiere un enfoque adicional: el habilitador. Inspirado en las ciencias del comportamiento, este modelo no solo reconoce las limitaciones humanas, sino también sus fortalezas. Un enfoque habilitador implica diseñar sistemas de seguridad que motiven y capaciten a los usuarios para tomar decisiones seguras por iniciativa propia, convirtiéndose en socios y no solo en piezas de un sistema rígido. No se pero yo no termino de ver eso de involucrar a un usuario en las políticas de seguridad.
Este cambio de paradigma implica capacitar a los usuarios para que respondan a amenazas emergentes, como ataques de phishing cada vez más sofisticados, es decir, fortalecer la resiliencia. Pero ¿cómo? Ademas, implica estudiar no solo los errores, sino también los éxitos y comportamientos positivos en seguridad para replicarlos y entender qué motiva a los usuarios a actuar de forma segura. Y en lugar de esperar que los usuarios sigan reglas impuestas, fomentar una cultura de seguridad donde los individuos se sientan responsables y comprometidos con la seguridad colectiva.
A ver cómo le explicas esto a un CISO.
Según el artículo, este nuevo enfoque ofrece una visión de la ciberseguridad que va más allá del control y la desconfianza. Considerar a los usuarios como socios en lugar de “enemigos” abre la puerta a una ciberseguridad más humana, eficiente y resiliente, preparada para afrontar los desafíos de un mundo digital en constante cambio.
Y esto, lectores, es para mí la pérdida completa de control sobre un sistema.
