Un molino llamado SMI: leer un BSOD con una IA local cuando el culpable no está donde Windows dice (CASO I)
Sobre
CrashDetectorwithAI, los handlers en SMM que se exceden, y por qué decodificar un fault bucket no es lo mismo que entender un crash.
1. El abismo entre «se ha reiniciado» y saber por qué.
Cualquiera que haya pasado más de diez minutos administrando sistemas Windows conoce el ritual. Pantalla azul, código de error en hexadecimal, QR que nadie escanea, reinicio, y un Visor de Eventos que escupe un BugCheckCode y un FaultBucketId con la misma vocación divulgativa que una inscripción en arameo. El usuario medio (y muchos profesionales) hace entonces lo previsible: copia el código, lo lanza a Google, lee tres hilos de Reddit de 2019, actualiza un driver al azar y, si la cosa no vuelve a romperse en una semana, declara cerrado el incidente.
El problema, claro, no es el ritual. El problema es que ese ritual confunde correlación supersticiosa con diagnóstico. Y en Windows, donde el crash que ves rara vez es el crash que ocurrió, esa diferencia importa.Especialmente porque puede revelar intentos de persistencia, intrusiones, o áreas de exposición de tu infraestructura (como el caso que veremos en este post, que versa sobre una utilidad de fabricante haciendo outb 0xB2 periódico lo que provoca la activación de un handler SMI con busy-wait sin timeout sobre el Embedded Controller esto genera una ventana SMM > umbral DPC watchdog y salta el DPC_WATCHDOG_VIOLATION) ver Fig. 1.
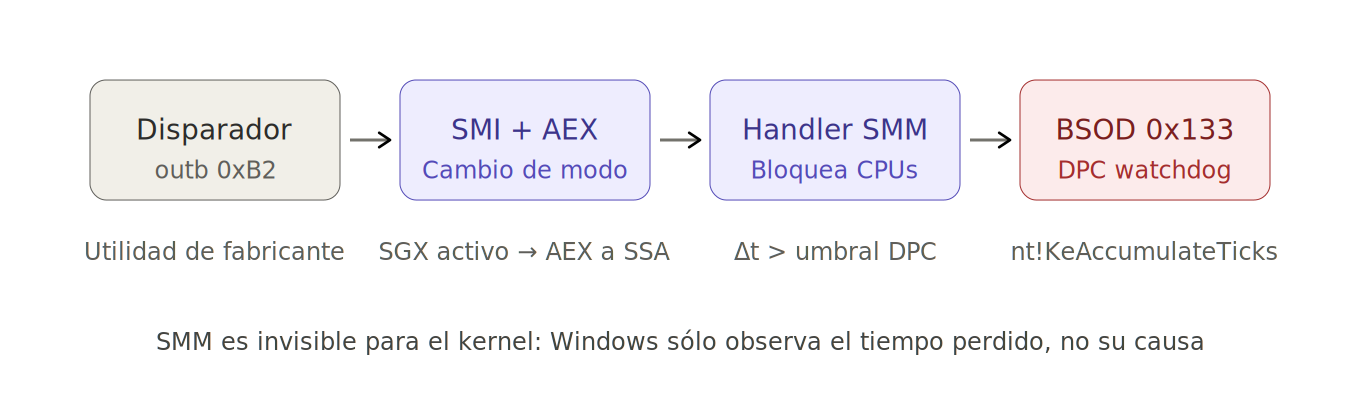
Fig. 1 — Anatomía del crash: el camino que va desde un outb 0xB2 inocente en espacio de usuario hasta la pantalla azul, pasando por dos modos de ejecución que Windows no puede instrumentar: una invocación SMI desde el modo de usuario (outb 0xB2) provoca, en sistemas con SGX activo, un Asynchronous Enclave Exit; el rendezvous SMM bloquea todos los núcleos mientras se ejecuta el handler; cuando el tiempo de espera supera el umbral, el kernel dispara DPC_WATCHDOG_VIOLATION.
El motivo de este post es probar una herramienta llamada CrashDetectorwithAI, de Claton Hendricks. Publicada bajo GPL-3.0 en GitHub (clatonhendricks/CrashDetectorwithAI), está construida con WPF sobre .NET 9 y ejecuta inferencia local de Phi-4 vía ONNX Runtime (con soporte alternativo a Ollama para quien prefiera Llama 3, Mistral, DeepSeek o Gemma). En cristiano: detecta eventos de crash, lee la información del fault bucket del Windows Error Reporting (WER) y se la entrega a un modelo pequeño que corre en tu máquina para devolverte una explicación legible y propuestas de solución, todo sin sacar un solo byte hacia la nube.
A primera vista parece un gadget de soporte técnico para cualquier usuario convencional. Y, en parte, lo es. Pero quien lleva tiempo en esto reconoce un segundo uso, mucho más interesante: es una herramienta didáctica para asomarse al subsistema de errores de Windows sin haberse leído antes los tres tomos de Russinovich. La gracia no está en que «te arregle el PC». La gracia está en que cada Blue Screen of Death (BSOD) se convierte en una oportunidad de aprender Windows por dentro.
Para ilustrarlo, os voy a desarrollar un caso realista (y, por motivos profesionales, que me ha ocurrido): un crash que Windows imputa formalmente a un driver inocente, cuando el verdadero culpable está varios anillos de privilegio más abajo, ejecutando en System Management Mode un handler que nunca debió ser tan generoso con el tiempo de espera (timeout).
2. Qué hay realmente debajo del capó del WER
Para no repetirme con mi entrada del 15 de mayo sobre SMM, SMI y forense en entornos SGX (donde tildé al SMM como sospechoso, no como aliado), basta un recordatorio rápido:
- Un System Management Interrupt (SMI) es la única interrupción que ningún sistema operativo puede enmascarar. La CPU abandona lo que esté haciendo, conmuta a System Management Mode, ejecuta un handler alojado en SMRAM y devuelve el control. Ese handler vive en firmware, no en el kernel de Windows.
- En la mayoría de plataformas Intel, el SMI es un rendezvous síncrono entre todos los núcleos lógicos: cuando uno entra en SMM, los demás esperan. Si el handler tarda 200 ms, todo el sistema ha estado parado 200 ms. Windows no ha visto ese tiempo: para él, simplemente, no ocurrió.
- WER, en cambio, sí ve las consecuencias: DPCs que no se entregan a tiempo, timers que no se sirven, watchdogs que se disparan. Y como WER no instrumenta SMM (no podría aunque quisiera), atribuye el accidente a la última víctima visible, normalmente un driver que llevaba encolada una DPC inocente.

Esta asimetría es la madre de un género entero de incidentes mal diagnosticados. El operador ve un DRIVER_VERIFIER_DETECTED_VIOLATION o un DPC_WATCHDOG_VIOLATION y, fiel al manual, jura y perjura contra el driver.

El driver, mientras tanto, mira de reojo a un handler de gestión térmica1 que se ha permitido un polling de 12 ms al Embedded Controller, multiplicado por los doce SMIs que dispara cada segundo una utilidad de fabricante que nadie pidió pero todos instalan.
3. La estación de trabajo que «falla aleatoriamente»
El escenario es banal. Windows 11, dos pantallas, treinta pestañas, un IDE, y la suite de monitorización térmica/RGB del fabricante de la placa base instalada de fábrica. Efectos:
- BSOD intermitentes, una o dos veces por semana.
- Bug check siempre el mismo:
0x133(DPC_WATCHDOG_VIOLATION). - Sin patrón aparente. A veces compilando, a veces viendo Netflix, a veces con la máquina prácticamente ociosa.
El primer reflejo (el malo) es revisar drivers gráficos, de red y de almacenamiento. El segundo (también malo) es pasar el verifier.exe en modo paranoico, lo que dispara más BSODs sin acercar la respuesta. El tercero (el útil) es preguntarse qué dice exactamente WER.
Verifier.exe (Administrador del Verificador de controladores) es una herramienta nativa de Windows diseñada para probar y depurar controladores de dispositivos (drivers). Su función principal es estresar los controladores del sistema en tiempo real para detectar fallos, corrupción de memoria o incompatibilidades antes de que provoquen bloqueos graves.
¿Para qué se utiliza?
- Diagnóstico de Pantallazos Azules (BSOD): Si tu sistema se bloquea frecuentemente, esta herramienta ayuda a identificar exactamente qué controlador está causando el error (y como vamos a ver, no siempre ese es el motivo).
- Validación de controladores: Comprueba si los drivers están firmados digitalmente o si fueron creados para versiones anteriores de Windows.
- Herramienta para desarrolladores: Ofrece opciones avanzadas para estresar la memoria I/O y registrar llamadas de sistema problemáticas.
Precauciones importantes
Dado que fuerza a los controladores a operar bajo condiciones extremas, puede causar pantallazos azules (BSOD) intencionales si detecta un fallo. Se recomienda utilizarlo únicamente en fases de depuración o cuando tu ordenador de uso diario esté experimentando fallos recurrentes y necesites encontrar al culpable.
Abrimos CrashDetectorwithAI tras el siguiente crash. La aplicación, sin que tengamos que tocar wer.dll ni rebuscar en C:\ProgramData\Microsoft\Windows\WER\ReportArchive\, presenta de forma estructurada algo equivalente a esto:
Crash event detected─────────────────────────────────────────────EventID: 1001 (BugCheck)BugCheckCode: 0x00000133Parameters: 0x0000000000000000 0x0000000000000501 0x0000000000000500 0xFFFFF80712345678FaultBucketId: 0x133_0_nt!KeAccumulateTicksReportSignature: BlueScreen / 133 / nt / 10.0.26100.xxxxWHEA records: none in last 5sMinidump: C:\Windows\Minidump\051826-...dmp
Y, debajo, la respuesta del modelo local (Phi-4 vía ONNX) en streaming, que viene a decir, con palabras propias y prudentes, algo como (traducido y simplificado para cualquier lector):
Se trata de un DPC_WATCHDOG_VIOLATION. El parámetro 1 con valor 0 indica que se ha superado el umbral acumulado de DPC en un solo procesador. Los valores 0x501 y 0x500 son los *ticks* observado y permitido, expresados en unidades del kernel. La dirección final apunta a nt!KeAccumulateTicks, lo cual es habitual: el watchdog se dispara desde la contabilidad de tiempo del kernel, no desde la DPC culpable. Causas frecuentes: driver con DPC excesivamente larga, problema de firmware/BIOS que bloquea la CPU, o controlador de almacenamiento (storport/NVMe) bajo estrés. Recomendaciones iniciales: actualizar BIOS, drivers de chipset y de almacenamiento; revisar utilidades de fabricante que interactúen con el firmware; ejecutar LatencyMon en estado normal de uso.
Hagamos un alto aquí, porquq esta IA me está diciendo cosas raras, raras.
4. Qué hace bien la IA local, y dónde se cohíbe por diseño
La respuesta anterior es útil y razonablemente correcta. Y, lo que me parece más relevante, está calibrada: no afirma que un driver concreto sea el culpable, no inventa números, y menciona la posibilidad de un problema de firmware. Para un usuario que de otro modo habría reinstalado el driver de la NVIDIA por tercera vez, es un salto cualitativo.
Pero conviene mirar también lo que la IA no puede saber, y que cualquier ingeniero con experiencia sabe inferir:
- El fault bucket es un agregador, no una causa.
133_0_nt!KeAccumulateTickssignifica literalmente «aquí saltó el contador», no «aquí estaba el bug». Quien escribió el agrupador de WER lo hizo para que Microsoft pueda agrupar millones de telemetrías por similitud, no para que tú identifiques al responsable. - WER no instrumenta SMM. No hay forma, desde el espacio kernel, de que
nt!KeAccumulateTickste diga «he perdido 400 ms porque el procesador estaba en Ring −2 ejecutando código de firmware». El kernel ve el reloj saltar, no quién lo robó. - Phi-4 (o cualquier modelo de propósito general de pocos miles de millones de parámetros) no ha leído tu DSDT, tu SSDT, ni el datasheet del chipset de tu placa. Sabe en abstracto que SMIs largos pueden disparar 0x133. No sabe si los tuyos lo están haciendo.
DSDT y SSDT son tablas ACPI fundamentales en el firmware de tu placa base que comunican al sistema operativo cómo funcionan componentes como la CPU, los puertos USB y la energía.
Diferencias Clave
- DSDT (Differentiated System Description Table): Es la tabla principal que describe la configuración base y todos los dispositivos principales del hardware de tu equipo. Solo existe una por sistema.
- SSDT (Secondary System Description Table): Son tablas secundarias y modulares que describen componentes específicos (como la gestión de energía de la CPU o tarjetas gráficas). Un sistema puede tener múltiples SSDTs.
La buena noticia es que estos tres techos son metodológicos, no propios de la herramienta. La herramienta hace lo que sabe hacer, y lo hace bien: traducir, contextualizar y orientar. Lo que sigue es trabajo humano y, sobre todo, instrumentación. Para que veáis que todavía la IA no os va a sustituir :).
5. Bajar al cuarto de máquinas: medir SMI desde el SO
Si sospechamos que el handler SMI es el problema, hay que demostrarlo. Windows expone, indirectamente, la información suficiente.
5.1. Contador de SMI por núcleo (MSR 0x34)
En procesadores Intel, el MSR 0x34 (MSR_SMI_COUNT) es un contador monotónico de SMIs servidos por ese núcleo lógico desde el último reset. Con RWEverything, ChipSec o un driver de lectura de MSRs, se obtiene una lectura trivial:
chipsec_util msr 0x34
En una máquina sana en idle, ese contador debería incrementarse del orden de unas pocas unidades por minuto, o menos. Si en una máquina con la utilidad del fabricante activa observamos algo como:
[CPU0] MSR 0x34 = 0x000000000001A47C (t=0s)[CPU0] MSR 0x34 = 0x000000000001A4F0 (t=10s) Δ = 116 SMIs / 10s
…es decir, en torno a 12 SMIs por segundo en reposo, ya tenemos un primer indicador objetivo. No prueba la causa, pero sí que algo en la plataforma está disparando SMIs con una frecuencia que ningún diseño térmico razonable justifica.
5.2. Latencia de SMI con LatencyMon o WPA
LatencyMon (Resplendence) ofrece el indicador clínico más legible: highest measured interrupt to process latency. En el caso que nos ocupa, valores > 1500 µs en hard pagefault path y > 4000 µs puntuales son banderas rojas. El propio LatencyMon, en sistemas afectados, suele mostrar el mensaje canónico: «Your system appears to be having difficulty handling real-time audio and other tasks. […] One or more DPC routines that belong to a driver running in your system appear to be executing for too long […]». Mensaje engañoso, porque el driver que aparece en la columna acumulada de DPC suele ser inocente: en realidad ha sido desplazado en el tiempo por la ventana SMM, y el contador lo acusa a él.

Más rigurosa es la traza con Windows Performance Recorder y el perfil de CPU usage + Power, abierta en Windows Performance Analyzer. La columna SMI del System Activity aparece, en una máquina afectada, como un peine regular de picos coincidiendo con cada disparo del handler.
5.3. Cruzar con WHEA
Aunque WER lo silencia, el subsistema WHEA (Microsoft-Windows-WHEA-Logger) a veces deja rastro: PCIe Correctable Errors sin sentido aparente, thermal throttling notifications periódicas, o eventos BIOS error record (Event ID 47). Cuando aparecen sincronizados con los picos de SMI, la hipótesis se refuerza.
6. El culpable: un handler térmico, generoso, que gasta tiempo como si la máquina fuera suya, disparado por una utilidad de RGB
En el caso real que motiva este artículo, el responsable resultó ser una combinación sorprendente:
- El servicio en segundo plano de la suite del fabricante cuya marca omito porque no quiero crear polémica (control de iluminación, perfiles térmicos, overclock asistido) escribe periódicamente en el puerto
0xB2(APMC, Advanced Power Management Control), el método canónico para invocar un software SMI y solicitar al firmware una lectura de sensores. - El handler SMI correspondiente en el firmware UEFI realiza esa lectura secuencialmente sobre el Embedded Controller vía protocolo ACPI EC, esperando handshakes del EC con un busy-wait sin timeout agresivo.
- Cada invocación gasta entre 150 y 400 µs en condiciones normales, pero ante una mínima contención del EC (por ejemplo, durante una transición de estado de la batería en portátiles, o coincidiendo con eventos de teclado en estaciones con KVMs USB) salta a 8–12 ms.
- Multiplicado por una cadencia de 10–15 SMIs/s, el sistema acumula ventanas SMM que, en el peor caso, superan el umbral del DPC watchdog y disparan el
0x133.
Lo elegante de este patrón es que WER no puede ver nada de lo anterior. Lo único que ve es que nt!KeAccumulateTicks se sorprendió de cuánto tiempo había pasado. Y el informe agrupado, así lo dice.
La resolución, una vez identificado el patrón, es banal:
- Actualización de BIOS a la versión donde el OEM corrige el busy-wait del handler de lectura de sensores (en este caso, una nota de release de tres líneas que sólo menciona «improved system stability under sustained sensor polling»).
- Desinstalación o, como mínimo, desactivación del servicio en segundo plano de la suite del fabricante; la lectura de sensores que necesite el usuario puede obtenerse con HWiNFO en lectura pasiva sin disparar SMIs adicionales.
- Verificación posterior:
MSR 0x34baja a <1 SMI/s en idle, LatencyMon vuelve a verde, y los0x133desaparecen del Visor de Eventos.
7. Volver a la herramienta: qué se aprende por el camino
Si has llegado hasta aquí siguiendo el post, te habrás dado cuenta de algo: CrashDetectorwithAI no diagnosticó el problema. No podía. Lo que hizo, y lo hizo bien, fue:
- Sacar a la luz el
FaultBucketIdy elBugCheckCodecon sus parámetros, sin que el usuario tuviera que rebuscar enWER\ReportArchive. - Traducirlos a una explicación calibrada y útil para empezar a pensar.
- Sugerir, entre otras cosas, «revisar utilidades de fabricante que interactúen con el firmware», que es exactamente el camino correcto.
- Recomendar
LatencyMon, que es la herramienta canónica para confirmar la hipótesis.
En otras palabras: el modelo local me puso en la pista correcta y se calló a tiempo. No fingió saber lo que no podía saber. No inventó un nombre de driver. No me mandó a desinstalar la GPU. Esa modestia, en una industria de chatbots que afirman con la misma confianza una verdad y un disparate, es una virtud técnica seria.
Hay además un argumento de soberanía que no quiero dejar pasar. La herramienta corre íntegramente en local: el fault bucket, los parámetros del BugCheck y, eventualmente, el contenido del minidump nunca salen de tu máquina. Para cualquier organización con datos sensibles, esto no es una preferencia estética: es la diferencia entre una herramienta usable y una herramienta vetada por cumplimiento. Phi-4 en ONNX Int4 ocupa una fracción de gigabyte y se ejecuta en CPU; Ollama abre la puerta a modelos mayores si la máquina lo soporta. En ambos casos, ningún tercero ve tus crashes.
8. Lecciones más allá del caso
Conviene formular en limpio:
- El crash que ves rara vez es el crash que ocurrió. WER agrupa por consecuencia; el
FaultBucketIdes un identificador estadístico, no un diagnóstico. - SMM es invisible para el SO. Cualquier explicación de un BSOD que ignore la existencia del Ring −2 está, por construcción, incompleta. En máquinas con utilidades de fabricante particularmente entusiastas con
outb 0xB2, esa incompletitud se vuelve operativa. - La IA local es un buen primer escalón, no el último. Su valor no está en sustituir al ingeniero, sino en acortar la distancia entre el código hexadecimal y la primera hipótesis razonable. Quien sabe leer un MSR no la necesita; quien no lo sabe, con ella aprende antes.
- Phi-4 corriendo en tu máquina con licencia GPL-3.0 no es un juguete. Es una demostración mundana, sin marketing, de para qué sirven realmente los modelos pequeños: convertir telemetría opaca en lenguaje natural sin entregar la telemetría a nadie.
La industria de la IA lleva tres años convenciéndonos de que su utilidad pasa por mandarlo todo a la nube. Herramientas como CrashDetectorwithAI recuerdan, con discreción, que también se puede al revés: traer el modelo a la máquina, dejar el dato quieto, y usar la inferencia para enseñar en lugar de opinar. Si alguna pedagogía de la administración de sistemas merece la pena en 2026, probablemente sea esta.
Y, claro, queda el viejo asunto de fondo: la BSOD seguirá llamándose pantalla azul, el 0x133 seguirá apuntando a nt!KeAccumulateTicks, y la próxima utilidad de RGB que alguien instale seguirá invocando outb 0xB2 con la inocencia del que cree que el firmware está para servirle. Don Quijote, recordemos, no se quejaba de que hubiera molinos. Se quejaba de que nadie quisiera mirarlos de cerca.
Referencias
- Clayton Hendricks. CrashDetectorwithAI. Repositorio GitHub: github.com/clatonhendricks/CrashDetectorwithAI. Licencia GPL-3.0.
- Microsoft Learn. Bug Check 0x133: DPC_WATCHDOG_VIOLATION.
- Intel. Intel® 64 and IA-32 Architectures Software Developer’s Manual, Vol. 3C — System Management Mode.
- Resplendence Software. LatencyMon: Real-time monitor for kernel latency.
Notas al pie
- Espero que algún estudiante de Periféricos e Interfaces llegue a leer esto, pero he aquí la importancia de entender la gestión térmica (como vimos en clase) porque disparará al SMI. ↩︎
